LangGraph 与模型代码


在本博客中,我们将引导您完成使用 MLflow 创建 LangGraph 聊天机器人。通过将 MLflow 与 LangGraph 创建和管理循环图的能力相结合,您可以以可扩展的方式创建强大的有状态、多参与者的应用程序。
在本文中,我们将演示如何利用 MLflow 的功能来创建一个可序列化且可服务的 MLflow 模型,该模型可以轻松地在各种服务器上进行跟踪、版本化和部署。我们将使用 Langchain 插件 结合 MLflow 的 代码模型 功能。
什么是 LangGraph?
LangGraph 是一个用于使用 LLM 构建有状态、多参与者应用程序的库,用于创建代理和多代理工作流。与其他人形 LLM 框架相比,它提供了这些核心优势:
- 循环和分支:在您的应用程序中实现循环和条件。
- 持久性:在图的每一步之后自动保存状态。可以随时暂停和恢复图执行,以支持错误恢复、人工干预工作流、时间旅行等。
- 人工干预:中断图执行,以批准或编辑代理计划的下一步操作。
- 流式传输支持:流式传输每个节点产生的输出(包括 token 流式传输)。
- 与 LangChain 集成:LangGraph 与 LangChain 无缝集成。
LangGraph 允许您定义涉及循环的流,这对于大多数代理架构至关重要,这使其与基于 DAG 的解决方案区分开来。作为一个非常底层的框架,它提供了对应用程序的流和状态的细粒度控制,这对于创建可靠的代理至关重要。此外,LangGraph 还包含内置持久性,支持高级的人工干预和内存功能。
LangGraph 的灵感来自 Pregel 和 Apache Beam。其公共接口的灵感来自 NetworkX。LangGraph 由 LangChain 的创建者 LangChain Inc. 构建,但也可以在不使用 LangChain 的情况下使用。
有关完整演练,请查看 LangGraph 快速入门,有关 LangGraph 设计基础知识的更多信息,请查看 概念指南。
1 - 设置
首先,我们必须安装所需的依赖项。在此示例中,我们将使用 OpenAI 作为我们的 LLM,但使用 LangChain 和 LangGraph 可以轻松替换任何支持的替代 LLM 或 LLM 提供商。
%%capture
%pip install langchain_openai==0.2.0 langchain==0.3.0 langgraph==0.2.27
%pip install -U mlflow
接下来,让我们获取相关的秘密。如 LangGraph 快速入门 中所示,使用 getpass 是将您的密钥插入交互式 Jupyter 环境的好方法。
import os
# Set required environment variables for authenticating to OpenAI
# Check additional MLflow tutorials for examples of authentication if needed
# https://mlflow.org.cn/docs/latest/llms/openai/guide/index.html#direct-openai-service-usage
assert "OPENAI_API_KEY" in os.environ, "Please set the OPENAI_API_KEY environment variable."
2 - 自定义工具
虽然这是一个演示,但将可重用工具分离到单独的文件/目录中是一种好习惯。下面我们创建三个通用的工具,理论上它们在构建其他 MLflow + LangGraph 实现时会很有价值。
请注意,我们在 Jupyter Notebook 环境中使用魔术命令 %%writefile 来创建一个新文件。如果您在交互式 Notebook 之外运行此命令,只需创建下面的文件,省略 %%writefile {FILE_NAME}.py 行。
%%writefile langgraph_utils.py
# omit this line if directly creating this file; this command is purely for running within Jupyter
import os
from typing import Union
from langgraph.pregel.io import AddableValuesDict
def _langgraph_message_to_mlflow_message(
langgraph_message: AddableValuesDict,
) -> dict:
langgraph_type_to_mlflow_role = {
"human": "user",
"ai": "assistant",
"system": "system",
}
if type_clean := langgraph_type_to_mlflow_role.get(langgraph_message.type):
return {"role": type_clean, "content": langgraph_message.content}
else:
raise ValueError(f"Incorrect role specified: {langgraph_message.type}")
def get_most_recent_message(response: AddableValuesDict) -> dict:
most_recent_message = response.get("messages")[-1]
return _langgraph_message_to_mlflow_message(most_recent_message)["content"]
def increment_message_history(
response: AddableValuesDict, new_message: Union[dict, AddableValuesDict]
) -> list[dict]:
if isinstance(new_message, AddableValuesDict):
new_message = _langgraph_message_to_mlflow_message(new_message)
message_history = [
_langgraph_message_to_mlflow_message(message)
for message in response.get("messages")
]
return message_history + [new_message]
完成此步骤后,您应该会在当前目录中看到一个名为 langgraph_utils.py 的新文件。
请注意,添加单元测试并将项目正确组织到逻辑结构化的目录中是最佳实践。
3 - 记录 LangGraph 模型
太好了!现在我们已经有了位于 ./langgraph_utils.py 的可重用工具,我们可以使用 MLflow 的官方 LangGraph 插件来记录模型了。
3.1 - 创建我们的代码模型文件
快速背景介绍。MLflow 会将模型伪像序列化到 MLflow 跟踪服务器。许多流行的 ML 包没有健壮的序列化和反序列化支持,因此 MLflow 会通过 代码模型 功能来增强此功能。通过代码模型,我们可以利用 Python 作为序列化格式,而不是 JSON 或 pkl 等流行替代方案。这带来了巨大的灵活性和稳定性。
要创建具有代码模型的 Python 文件,我们必须执行以下步骤:
- 创建一个新的 Python 文件。我们称之为
graph.py。 - 定义我们的 LangGraph 图。
- 利用 mlflow.models.set_model 来指示 MLflow Python 脚本中的哪个对象是我们感兴趣的模型。
就是这样!
%%writefile graph.py
# omit this line if directly creating this file; this command is purely for running within Jupyter
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.graph.state import CompiledStateGraph
import mlflow
import os
from typing import TypedDict, Annotated
def load_graph() -> CompiledStateGraph:
"""Create example chatbot from LangGraph Quickstart."""
assert "OPENAI_API_KEY" in os.environ, "Please set the OPENAI_API_KEY environment variable."
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
llm = ChatOpenAI()
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()
return graph
# Set are model to be leveraged via model from code
mlflow.models.set_model(load_graph())
3.2 - 使用“代码模型”进行记录
创建此实现后,我们可以利用标准的 MLflow API 来记录模型。
import mlflow
with mlflow.start_run() as run_id:
model_info = mlflow.langchain.log_model(
lc_model="graph.py", # Path to our model Python file
artifact_path="langgraph",
)
model_uri = model_info.model_uri
4 - 使用记录的模型
现在我们已成功记录了一个模型,我们可以加载它并将其用于推理。
在下面的代码中,我们演示了我们的链具有聊天机器人功能!
import mlflow
# Custom utilities for handling chat history
from langgraph_utils import (
increment_message_history,
get_most_recent_message,
)
# Enable tracing
mlflow.set_experiment("Tracing example") # In Databricks, use an absolute path. Visit Databricks docs for more.
mlflow.langchain.autolog()
# Load the model
loaded_model = mlflow.langchain.load_model(model_uri)
# Show inference and message history functionality
print("-------- Message 1 -----------")
message = "What's my name?"
payload = {"messages": [{"role": "user", "content": message}]}
response = loaded_model.invoke(payload)
print(f"User: {message}")
print(f"Agent: {get_most_recent_message(response)}")
print("\n-------- Message 2 -----------")
message = "My name is Morpheus."
new_messages = increment_message_history(response, {"role": "user", "content": message})
payload = {"messages": new_messages}
response = loaded_model.invoke(payload)
print(f"User: {message}")
print(f"Agent: {get_most_recent_message(response)}")
print("\n-------- Message 3 -----------")
message = "What is my name?"
new_messages = increment_message_history(response, {"role": "user", "content": message})
payload = {"messages": new_messages}
response = loaded_model.invoke(payload)
print(f"User: {message}")
print(f"Agent: {get_most_recent_message(response)}")
输出
-------- Message 1 -----------
User: What's my name?
Agent: I'm sorry, I cannot guess your name as I do not have access to that information. If you would like to share your name with me, feel free to do so.
-------- Message 2 -----------
User: My name is Morpheus.
Agent: Nice to meet you, Morpheus! How can I assist you today?
-------- Message 3 -----------
User: What is my name?
Agent: Your name is Morpheus.
4.1 - MLflow 跟踪
在结束之前,让我们演示一下 MLflow 跟踪。
MLflow 跟踪是一项功能,可通过捕获有关应用程序服务执行的详细信息来增强生成式 AI (GenAI) 应用程序中的 LLM 可观察性。跟踪提供了一种记录请求的每个中间步骤的输入、输出和元数据的方法,使您能够轻松查明错误和意外行为的来源。
按照 跟踪服务器文档 中的说明启动 MLflow 服务器。进入 MLflow UI 后,我们可以看到我们的实验和相应的跟踪。

如您所见,我们已记录了跟踪,可以通过单击我们感兴趣的实验,然后单击“跟踪”选项卡轻松查看它们。
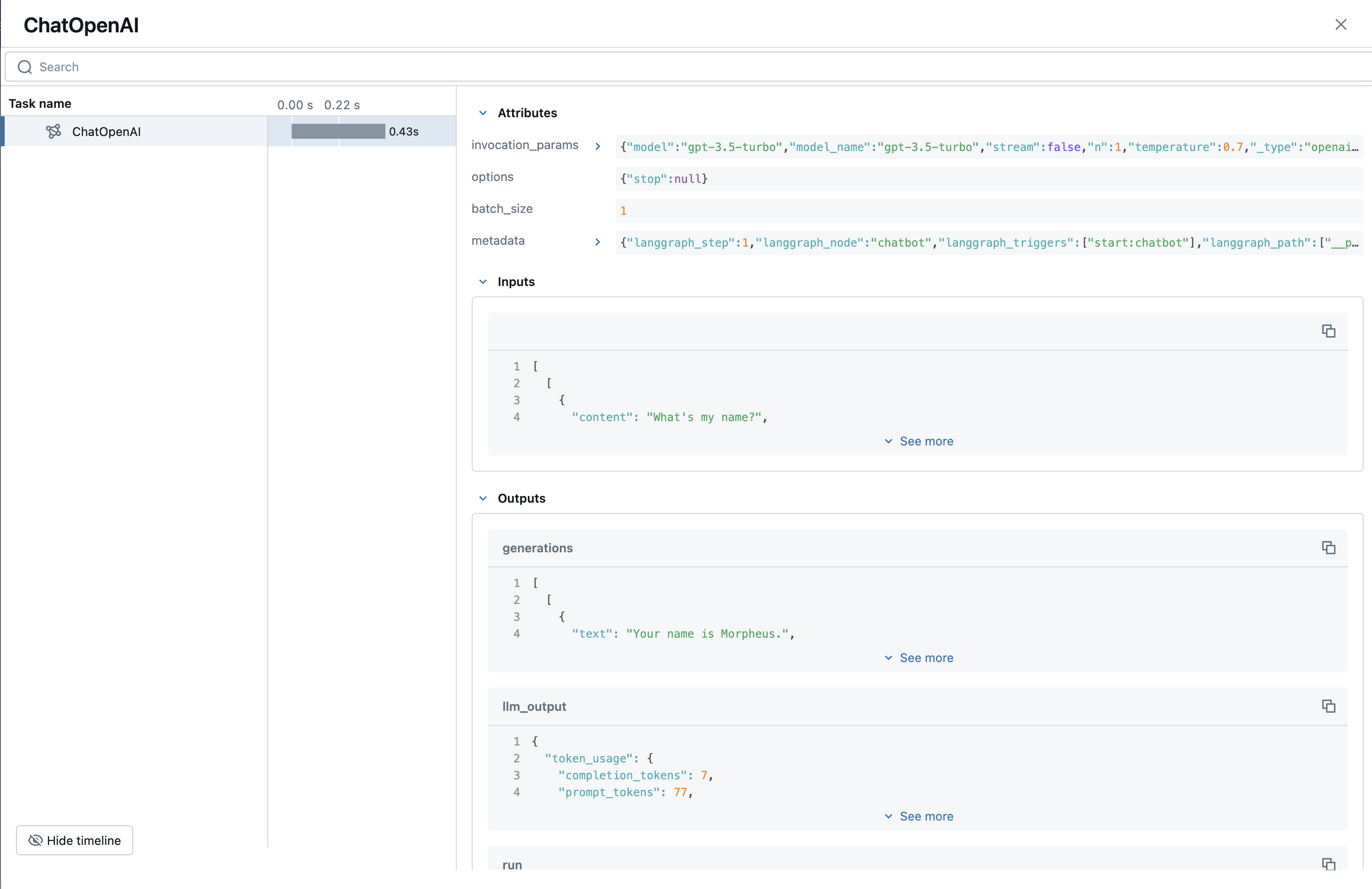
单击其中一个跟踪后,我们现在可以看到单个查询的运行执行。请注意,我们记录了输入、输出以及大量有用的元数据,例如使用情况和调用参数。随着我们的应用程序在用法和复杂性方面不断扩展,这个线程安全且高性能的跟踪系统将确保对应用程序进行稳健的监控。
5 - 总结
本教程有许多逻辑上的扩展,然而 MLflow 组件可以保持大体不变。例如,将聊天记录持久化到数据库、实现更复杂的 LangGraph 对象、将此解决方案投入生产等等!
总结一下,本教程涵盖了以下内容:
祝您编码愉快!