PyFunc 实践




如果您希望充分利用 mlflow.pyfunc 的功能,并了解如何在机器学习项目中加以利用,那么本博文将引导您完成整个过程。MLflow PyFunc 提供了创作自由度和灵活性,允许将复杂的系统开发为 MLflow 中的模型,并遵循与传统模型相同的生命周期。本博文将展示如何创建多模型设置、无缝连接到数据库以及在 MLflow PyFunc 模型中实现自己的自定义拟合方法。
简介
本博文演示了 MLflow PyFunc 的功能,以及如何利用它来构建一个在 MLflow 中被封装为 PyFunc 风味模型的“多模型设置”。这种方法允许集成模型遵循 MLflow 中与传统 内置模型风味 相同的生命周期。
但首先,让我们用一个类比来帮助您熟悉集成模型(ensemble models)的概念,以及为什么您应该在下一个机器学习项目中考虑这种解决方案。
想象一下您正在市场上购买房屋。您会仅仅根据第一次看房和一位房地产经纪人的建议就做出决定吗?当然不会!购房过程涉及考虑多个因素并从各种来源收集信息,以做出明智的决定。
购房过程说明
- 确定您的需求:确定您想要新房还是二手房、房屋类型、型号和建造年份。
- 研究:查找可用房屋列表,查看折扣和优惠,阅读客户评论,并寻求朋友和家人的意见。
- 评估:考虑性能、位置、社区便利设施和价格范围。
- 比较:比较多套房屋,找到最符合您需求和预算的选择。
简而言之,您不会直接得出结论,而是会考虑所有上述因素后再做出决定,选择最佳方案。
机器学习中的集成模型(ensemble models)遵循类似的思路。集成学习通过组合多个模型来提高机器学习结果,与单个模型相比,其预测性能更佳。性能的提升可能源于多种因素,例如通过对多个模型进行平均来减少方差,或通过关注先前模型的错误来减少偏差。存在多种集成学习技术,例如:
- 平均
- 加权平均
- Bagging
- Boosting
- Stacking
然而,开发此类系统需要对集成模型的生命周期进行仔细管理,因为集成不同模型可能非常复杂。这时 MLflow PyFunc 就显得尤为宝贵。它提供了构建复杂系统的灵活性,将整个集成作为模型来处理,该模型遵循与传统模型相同的生命周期流程。本质上,MLflow PyFunc 允许创建针对集成模型量身定制的自定义方法,作为流行框架(如 scikit-learn、PyTorch 和 LangChain)内置 MLflow 风味的替代方案。
本博文将使用来自 Kaggle 的房屋价格数据集来演示通过 MLflow 进行集成模型的开发和管理。
我们将利用各种工具和技术来突出 MLflow PyFunc 模型的功能。在深入研究集成模型本身之前,我们将探讨这些组件如何集成以创建一个健壮高效的机器学习管道。
项目组成部分
DuckDB
DuckDB 是一个高性能的分析数据库系统,旨在实现快速、可靠、便携且易于使用。在本项目中,它展示了在模型上下文中集成数据库连接,从而直接在模型内实现高效的数据处理。 了解更多关于 DuckDB 的信息。
scikit-learn (sklearn)
scikit-learn 是一个 Python 的机器学习库,提供高效的数据分析和建模工具。在本项目中,它用于开发和评估集成到我们集成模型中的各种机器学习模型。 了解更多关于 scikit-learn 的信息。
MLflow
MLflow 是一个开源平台,用于管理端到端的机器学习生命周期,包括实验、可复现性和部署。在本项目中,它跟踪实验、管理模型版本,并以类似于我们熟悉的单个风味的方式,促进 MLflow PyFunc 模型的部署。 了解更多关于 MLflow 的信息。
注意: 要复现本项目,请参阅官方 MLflow 文档,了解设置简单的本地 MLflow 跟踪服务器 的更多详细信息。
创建集成模型
创建 MLflow PyFunc 集成模型比使用内置风味来记录和处理流行的机器学习框架需要额外的步骤。
要实现集成模型,您需要定义一个 mlflow.pyfunc 模型,这涉及创建一个继承自 PythonModel 类的 Python 类,并实现其构造函数和类方法。虽然创建 PyFunc 模型的基本要求是实现 predict 方法,但集成模型需要额外的方法来管理模型并获得多模型预测。实例化集成模型后,您必须使用自定义 fit 方法来训练集成模型的子模型。与开箱即用的 MLflow 模型类似,您需要在训练运行期间将模型及其工件一起记录下来,然后在 MLflow 模型注册表中注册该模型。还将为模型添加一个 production 别名,以简化模型更新和推理。模型别名允许您为已注册模型的特定版本分配一个可变的、命名的引用。通过将别名分配给特定的模型版本,可以通过模型 URI 或模型注册表 API 轻松引用它。此设置允许在不更改服务工作负载代码的情况下,无缝更新用于推理的模型版本。有关更多详细信息,请参阅 使用别名和标签部署和组织模型。
以下部分(如图所示)详细介绍了集成模型的每个方法的实现,从而全面了解如何使用 MLflow PyFunc 定义、管理和利用集成模型。

在深入了解每个方法的详细实现之前,我们首先回顾一下 EnsembleModel 类的骨架。此骨架可作为理解集成模型结构的蓝图。后续部分将概述 MLflow PyFunc 提供的默认方法以及为集成模型实现的自定义方法,并提供代码。
这是 EnsembleModel 类的骨架
import mlflow
class EnsembleModel(mlflow.pyfunc.PythonModel):
"""Ensemble model class leveraging Pyfunc for multi-model integration in MLflow."""
def __init__(self):
"""Initialize the EnsembleModel instance."""
...
def add_strategy_and_save_to_db(self):
"""Add strategies to the DuckDB database."""
...
def feature_engineering(self):
"""Perform feature engineering on input data."""
...
def initialize_models(self):
"""Initialize models and their hyperparameter grids."""
...
def fit(self):
"""Train the ensemble of models."""
...
def predict(self):
"""Predict using the ensemble of models."""
...
def load_context(self):
"""Load the preprocessor and models from the MLflow context."""
...
初始化 EnsembleModel
集成模型中的构造函数对于设置其基本要素至关重要。它会建立预处理器、存储训练模型的字典、DuckDB 数据库路径以及用于管理不同集成策略的 pandas DataFrame 等关键属性。此外,它利用 initialize_models 方法来定义集成到其中的子模型。
import pandas as pd
def __init__(self):
"""
Initializes the EnsembleModel instance.
Sets up an empty preprocessing pipeline, a dictionary for fitted models,
and a DataFrame to store strategies. Also calls the method to initialize sub-models.
"""
self.preprocessor = None
self.fitted_models = {}
self.db_path = None
self.strategies = pd.DataFrame(columns=["strategy", "model_list", "weights"])
self.initialize_models()
添加策略并保存到数据库
自定义定义的 add_strategy_and_save_to_db 方法允许将新的集成策略添加到模型中,并将它们存储在 DuckDB 数据库中。此方法接受包含策略的 pandas DataFrame 和数据库路径作为输入。它将新策略附加到现有策略,并将它们保存在集成模型初始化期间指定的数据库中。此方法有助于管理各种集成策略并确保其持久存储以供将来使用。
import duckdb
import pandas as pd
def add_strategy_and_save_to_db(self, strategy_df: pd.DataFrame, db_path: str) -> None:
"""Add strategies from a DataFrame and save them to the DuckDB database.
Args:
strategy_df (pd.DataFrame): DataFrame containing strategies.
db_path (str): Path to the DuckDB database.
"""
# Update the instance-level database path for the current object
self.db_path = db_path
# Attempt to concatenate new strategies with the existing DataFrame
try:
self.strategies = pd.concat([self.strategies, strategy_df], ignore_index=True)
except Exception as e:
# Print an error message if any exceptions occur during concatenation
print(f"Error concatenating DataFrames: {e}")
return # Exit early to prevent further errors
# Use context manager for the database connection
try:
with duckdb.connect(self.db_path) as con:
# Register the strategies DataFrame as a temporary table in DuckDB
con.register("strategy_df", self.strategies)
# Drop any existing strategies table and create a new one with updated strategies
con.execute("DROP TABLE IF EXISTS strategies")
con.execute("CREATE TABLE strategies AS SELECT * FROM strategy_df")
except Exception as e:
# Print an error message if any exceptions occur during database operations
print(f"Error executing database operations: {e}")
以下示例演示了如何使用此方法将策略添加到数据库。
import pandas as pd
# Initialize ensemble model
ensemble_model = EnsembleModel()
# Define strategies for the ensemble model
strategy_data = {
"strategy": ["average_1"],
"model_list": ["random_forest,xgboost,decision_tree,gradient_boosting,adaboost"],
"weights": ["1"],
}
# Create a DataFrame to hold the strategy information
strategies_df = pd.DataFrame(strategy_data)
# Add strategies to the database
ensemble_model.add_strategy_and_save_to_db(strategies_df, "models/strategies.db")
DataFrame strategy_data 包含
- strategy:模型预测策略的名称。
- model_list:
model_list中模型名称的逗号分隔列表。 - weights:
model_list中每个模型分配的权重的逗号分隔列表。如果未提供,则表示权重相等或使用默认值。
| strategy | model_list | weights |
|---|---|---|
| average_1 | random_forest,xgboost,decision_tree,gradient_boosting,adaboost | 1 |
特征工程
feature_engineering 方法通过处理缺失值、缩放数值特征和编码分类特征来预处理输入数据。它对数值和分类特征应用不同的转换,并将处理后的特征作为 NumPy 数组返回。此方法对于将数据准备成适合模型训练的格式至关重要,可确保一致性并提高模型性能。
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
def feature_engineering(self, X: pd.DataFrame) -> np.ndarray:
"""
Applies feature engineering to the input data X, including imputation, scaling, and encoding.
Args:
X (pd.DataFrame): Input features with potential categorical and numerical columns.
Returns:
np.ndarray: Processed feature array after transformations.
"""
# Convert columns with 'object' dtype to 'category' dtype for proper handling of categorical features
X = X.apply(
lambda col: col.astype("category") if col.dtypes == "object" else col
)
# Identify categorical and numerical features from the DataFrame
categorical_features = X.select_dtypes(include=["category"]).columns
numerical_features = X.select_dtypes(include=["number"]).columns
# Define the pipeline for numerical features: imputation followed by scaling
numeric_transformer = Pipeline(
steps=[
(
"imputer",
SimpleImputer(strategy="median"),
), # Replace missing values with the median
(
"scaler",
StandardScaler(),
), # Standardize features by removing the mean and scaling to unit variance
]
)
# Define the pipeline for categorical features: imputation followed by one-hot encoding
categorical_transformer = Pipeline(
steps=[
(
"imputer",
SimpleImputer(strategy="most_frequent"),
), # Replace missing values with the most frequent value
(
"onehot",
OneHotEncoder(handle_unknown="ignore"),
), # Encode categorical features as a one-hot numeric array
]
)
# Create a ColumnTransformer to apply the appropriate pipelines to the respective feature types
preprocessor = ColumnTransformer(
transformers=[
(
"num",
numeric_transformer,
numerical_features,
), # Apply the numeric pipeline to numerical features
(
"cat",
categorical_transformer,
categorical_features,
), # Apply the categorical pipeline to categorical features
]
)
# Fit and transform the input data using the preprocessor
X_processed = preprocessor.fit_transform(X)
# Store the preprocessor for future use in the predict method
self.preprocessor = preprocessor
return X_processed
初始化模型
initialize_models 方法设置一个包含各种机器学习模型的字典,以及它们的超参数网格。这包括 RandomForest、XGBoost、DecisionTree、GradientBoosting 和 AdaBoost 等模型。此步骤对于准备集成的子模型以及指定训练期间要调整的超参数至关重要,可确保每个模型都配置正确并准备好进行训练。
from sklearn.ensemble import (
AdaBoostRegressor,
GradientBoostingRegressor,
RandomForestRegressor,
)
from sklearn.tree import DecisionTreeRegressor
from xgboost import XGBRegressor
def initialize_models(self) -> None:
"""
Initializes a dictionary of models along with their hyperparameter grids for grid search.
"""
# Define various regression models with their respective hyperparameter grids for tuning
self.models = {
"random_forest": (
RandomForestRegressor(random_state=42),
{"n_estimators": [50, 100, 200], "max_depth": [None, 10, 20]},
),
"xgboost": (
XGBRegressor(random_state=42),
{"n_estimators": [50, 100, 200], "max_depth": [3, 6, 10]},
),
"decision_tree": (
DecisionTreeRegressor(random_state=42),
{"max_depth": [None, 10, 20]},
),
"gradient_boosting": (
GradientBoostingRegressor(random_state=42),
{"n_estimators": [50, 100, 200], "max_depth": [3, 5, 7]},
),
"adaboost": (
AdaBoostRegressor(random_state=42),
{"n_estimators": [50, 100, 200], "learning_rate": [0.01, 0.1, 1.0]},
),
}
定义自定义 fit 方法来训练和保存多模型
如前一个方法中已强调的,MLflow PyFunc 模型的一个关键特性是能够定义自定义方法,为各种任务提供显着的灵活性和定制性。在多模型 PyFunc 设置中,fit 方法对于自定义和优化多个子模型至关重要。它负责管理 RandomForestRegressor、XGBRegressor、DecisionTreeRegressor、GradientBoostingRegressor 和 AdaBoostRegressor 等算法的训练和微调。出于演示目的,使用了 Grid Search,虽然简单,但可能计算量大且耗时,尤其是对于集成模型。为了提高效率,建议采用高级优化方法,例如贝叶斯优化。诸如 Optuna 和 Hyperopt 等工具利用概率模型智能地导航搜索空间,从而显着减少了识别最佳配置所需的评估次数。
import os
import joblib
import pandas as pd
from sklearn.model_selection import GridSearchCV
def fit(
self, X_train_processed: pd.DataFrame, y_train: pd.Series, save_path: str
) -> None:
"""
Trains the ensemble of models using the provided preprocessed training data.
Args:
X_train_processed (pd.DataFrame): Preprocessed feature matrix for training.
y_train (pd.Series): Target variable for training.
save_path (str): Directory path where trained models will be saved.
"""
# Create the directory for saving models if it does not exist
os.makedirs(save_path, exist_ok=True)
# Iterate over each model and its parameter grid
for model_name, (model, param_grid) in self.models.items():
# Perform GridSearchCV to find the best hyperparameters for the current model
grid_search = GridSearchCV(
model, param_grid, cv=5, n_jobs=-1, scoring="neg_mean_squared_error"
)
grid_search.fit(
X_train_processed, y_train
) # Fit the model with the training data
# Save the best estimator from GridSearchCV
best_model = grid_search.best_estimator_
self.fitted_models[model_name] = best_model
# Save the trained model to disk
joblib.dump(best_model, os.path.join(save_path, f"{model_name}.pkl"))
定义自定义 predict 方法来聚合多模型预测
为了简化推理过程,每个 PyFunc 模型都应定义一个自定义 predict 方法作为推理的单一入口点。此方法在推理时抽象了模型的内部工作原理,无论是在处理自定义 PyFunc 模型还是处理流行 ML 框架的开箱即用的 MLflow 内置风味。
集成模型的自定义 predict 方法旨在收集和组合子模型的预测,支持各种聚合策略(例如,平均、加权)。该过程包括以下步骤:
- 根据用户定义的方法加载子模型预测聚合策略。
- 加载用于推理的模型。
- 预处理输入数据。
- 收集各个模型的预测。
- 根据指定的策略聚合模型预测。
import duckdb
import joblib
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
def predict(self, context, model_input: pd.DataFrame) -> np.ndarray:
"""
Predicts the target variable using the ensemble of models based on the selected strategy.
Args:
context: MLflow context object.
model_input (pd.DataFrame): Input features for prediction.
Returns:
np.ndarray: Array of predicted values.
Raises:
ValueError: If the strategy is unknown or no models are fitted.
"""
# Check if the 'strategy' column is present in the input DataFrame
if "strategy" in model_input.columns:
# Extract the strategy and drop it from the input features
print(f"Strategy: {model_input['strategy'].iloc[0]}")
strategy = model_input["strategy"].iloc[0]
model_input.drop(columns=["strategy"], inplace=True)
else:
# Default to 'average' strategy if none is provided
strategy = "average"
# Load the strategy details from the pre-loaded strategies DataFrame
loaded_strategy = self.strategies[self.strategies["strategy"] == strategy]
if loaded_strategy.empty:
# Raise an error if the specified strategy is not found
raise ValueError(
f"Strategy '{strategy}' not found in the pre-loaded strategies."
)
# Parse the list of models to be used for prediction
model_list = loaded_strategy["model_list"].iloc[0].split(",")
# Transform input features using the preprocessor, if available
if self.preprocessor is None:
# Feature engineering is required if the preprocessor is not set
X_processed = self.feature_engineering(model_input)
else:
# Use the existing preprocessor to transform the features
X_processed = self.preprocessor.transform(model_input)
if not self.fitted_models:
# Raise an error if no models are fitted
raise ValueError("No fitted models found. Please fit the models first.")
# Collect predictions from all models specified in the strategy
predictions = np.array(
[self.fitted_models[model].predict(X_processed) for model in model_list]
)
# Apply the specified strategy to combine the model predictions
if "average" in strategy:
# Calculate the average of predictions from all models
return np.mean(predictions, axis=0)
elif "weighted" in strategy:
# Extract weights from the strategy and normalize them
weights = [float(w) for w in loaded_strategy["weights"].iloc[0].split(",")]
weights = np.array(weights)
weights /= np.sum(weights) # Ensure weights sum to 1
# Compute the weighted average of predictions
return np.average(predictions, axis=0, weights=weights)
else:
# Raise an error if an unknown strategy is encountered
raise ValueError(f"Unknown strategy: {strategy}")
定义 load_context 自定义方法来初始化集成模型
当使用 mlflow.pyfunc.load_model 加载集成模型时,将执行自定义 load_context 方法,以在推理之前处理必要的模型初始化步骤。
此初始化过程包括:
- 使用包含工件引用的 context 对象加载模型工件,包括预训练模型和预处理器。
- 从 DuckDB 数据库获取策略定义。
import duckdb
import joblib
import pandas as pd
def load_context(self, context) -> None:
"""
Loads the preprocessor and models from the MLflow context.
Args:
context: MLflow context object which provides access to saved artifacts.
"""
# Load the preprocessor if its path is specified in the context artifacts
preprocessor_path = context.artifacts.get("preprocessor", None)
if preprocessor_path:
self.preprocessor = joblib.load(preprocessor_path)
# Load each model from the context artifacts and store it in the fitted_models dictionary
for model_name in self.models.keys():
model_path = context.artifacts.get(model_name, None)
if model_path:
self.fitted_models[model_name] = joblib.load(model_path)
else:
# Print a warning if a model is not found in the context artifacts
print(
f"Warning: {model_name} model not found in artifacts. Initialized but not fitted."
)
# Reconnect to the DuckDB database to load the strategies
conn = duckdb.connect(self.db_path)
# Fetch strategies from the DuckDB database into the strategies DataFrame
self.strategies = conn.execute("SELECT * FROM strategies").fetchdf()
# Close the database connection
conn.close()
整合所有内容
在详细探讨了每个方法之后,下一步是集成它们以观察完整的实现。这将全面展示组件如何交互以实现项目的目标。
您可以使用 创建集成模型 部分提供的骨架来组装整个 EnsembleModel 类。每个方法都已包含其特定依赖项进行了演示。现在,您只需按照提供的概述将这些方法合并到类定义中。随时添加适合您特定用例或增强集成模型功能的任何自定义逻辑。
在所有内容都封装在 PyFunc 模型中后,集成模型的生命周期将与传统 MLflow 模型非常相似。下图描绘了模型的生命周期。

MLflow 跟踪
使用 fit 方法训练子模型
数据预处理完成后,我们将使用自定义 fit 方法来训练我们集成模型中的所有子模型。此方法应用网格搜索来查找每个子模型的最佳超参数,将它们拟合到训练数据,并保存训练好的模型以供将来使用。
注意: 对于以下代码块,如果您不使用托管 MLflow,则可能需要设置 MLflow 跟踪服务器。在 项目组成部分 中,有一个关于设置简单本地 MLflow 跟踪服务器的说明。对于项目的此步骤,您需要将 MLflow 指向已配置并正在运行的服务器的 URI。不要忘记设置服务器 URI 变量
remote_server_uri。有关 记录到跟踪服务器 的更多详细信息,您可以参考官方 MLflow 文档。
import datetime
import os
import joblib
import mlflow
import pandas as pd
from mlflow.models.signature import infer_signature
from sklearn.model_selection import train_test_split
# Initialize the MLflow client
client = mlflow.MlflowClient()
# Set the URI of your MLflow Tracking Server
remote_server_uri = "..." # Replace with your server URI
# Point MLflow to your MLflow Tracking Server
mlflow.set_tracking_uri(remote_server_uri)
# Set the experiment name for organizing runs in MLflow
mlflow.set_experiment("Ensemble Model")
# Load dataset from the provided URL
data = pd.read_csv(
"https://github.com/zobi123/Machine-Learning-project-with-Python/blob/master/Housing.csv?raw=true"
)
# Separate features and target variable
X = data.drop("price", axis=1)
y = data["price"]
# Split dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Create a directory to save the models and related files
os.makedirs("models", exist_ok=True)
# Initialize and train the EnsembleModel
ensemble_model = EnsembleModel()
# Preprocess the training data using the defined feature engineering method
X_train_processed = ensemble_model.feature_engineering(X_train)
# Fit the models with the preprocessed training data and save them
ensemble_model.fit(X_train_processed, y_train, save_path="models")
# Infer the model signature using a small example from the training data
example_input = X_train[:1] # Use a single sample for signature inference
example_input["strategy"] = "average"
example_output = y_train[:1]
signature = infer_signature(example_input, example_output)
# Save the preprocessing pipeline to disk
joblib.dump(ensemble_model.preprocessor, "models/preprocessor.pkl")
# Define strategies for the ensemble model
strategy_data = {
"strategy": [
"average_1",
"average_2",
"weighted_1",
"weighted_2",
"weighted_3",
"weighted_4",
],
"model_list": [
"random_forest,xgboost,decision_tree,gradient_boosting,adaboost",
"decision_tree",
"random_forest,xgboost,decision_tree,gradient_boosting,adaboost",
"random_forest,xgboost,gradient_boosting",
"decision_tree,adaboost",
"xgboost,gradient_boosting",
],
"weights": ["1", "1", "0.2,0.3,0.1,0.2,0.2", "0.4,0.4,0.2", "0.5,0.5", "0.7,0.3"],
}
# Create a DataFrame to hold the strategy information
strategies_df = pd.DataFrame(strategy_data)
# Add strategies to the database
ensemble_model.add_strategy_and_save_to_db(strategies_df, "models/strategies.db")
# Define the Conda environment configuration for the MLflow model
conda_env = {
"name": "mlflow-env",
"channels": ["conda-forge"],
"dependencies": [
"python=3.8",
"scikit-learn=1.3.0",
"xgboost=2.0.3",
"joblib=1.2.0",
"pandas=1.5.3",
"numpy=1.23.5",
"duckdb=1.0.0",
{
"pip": [
"mlflow==2.14.1",
]
},
],
}
# Get current timestamp
timestamp = datetime.datetime.now().isoformat()
# Log the model using MLflow
with mlflow.start_run(run_name=timestamp) as run:
# Log parameters, artifacts, and model signature
mlflow.log_param("model_type", "EnsembleModel")
artifacts = {
model_name: os.path.join("models", f"{model_name}.pkl")
for model_name in ensemble_model.models.keys()
}
artifacts["preprocessor"] = os.path.join("models", "preprocessor.pkl")
artifacts["strategies_db"] = os.path.join("models", "strategies.db")
mlflow.pyfunc.log_model(
artifact_path="ensemble_model",
python_model=ensemble_model,
artifacts=artifacts,
conda_env=conda_env,
signature=signature,
)
print(f"Model logged in run {run.info.run_id}")
使用 MLflow 注册模型
模型训练完成后,下一步是将集成模型注册到 MLflow。此过程包括将训练好的模型、预处理管道和相关策略记录到 MLflow 跟踪服务器。这确保集成模型的所有组件都得到系统地保存和版本控制,从而促进可复现性和可追溯性。
此外,我们将为模型的初始版本分配一个生产别名。此指定将建立一个基准模型,未来迭代可以据此进行评估。通过将此版本标记为 production 模型,我们可以有效地进行改进基准测试,并确认后续版本比此已建立的基准有可衡量的进步。
# Register the model in MLflow and assign a production alias
model_uri = f"runs:/{run.info.run_id}/ensemble_model"
model_details = mlflow.register_model(model_uri=model_uri, name="ensemble_model")
client.set_registered_model_alias(
name="ensemble_model", alias="production", version=model_details.version
)
下图展示了我们的集成模型在 MLflow UI 中直至此步骤的完整生命周期。

使用 predict 方法执行推理
集成模型已注册到 MLflow 模型注册表中后,现在可以通过聚合集成中各个子模型的预测来利用它来预测房屋价格。
import pandas as pd
import mlflow
from sklearn.metrics import r2_score
# Load the registered model using its alias
loaded_model = mlflow.pyfunc.load_model(
model_uri=f"models:/ensemble_model@production"
)
# Define the different strategies for evaluation
strategies = [
"average_1",
"average_2",
"weighted_1",
"weighted_2",
"weighted_3",
"weighted_4",
]
# Initialize a DataFrame to store the results of predictions
results_df = pd.DataFrame()
# Iterate over each strategy, make predictions, and calculate R^2 scores
for strategy in strategies:
# Create a test DataFrame with the current strategy
X_test_with_params = X_test.copy()
X_test_with_params["strategy"] = strategy
# Use the loaded model to make predictions
y_pred = loaded_model.predict(X_test_with_params)
# Calculate R^2 score for the predictions
r2 = r2_score(y_test, y_pred)
# Store the results and R^2 score in the results DataFrame
results_df[strategy] = y_pred
results_df[f"r2_{strategy}"] = r2
# Add the actual target values to the results DataFrame
results_df["y_test"] = y_test.values
与开箱即用的 MLflow 模型类似,您首先使用 mlflow.pyfunc.load_model 加载集成模型来生成房屋价格预测。在定义了用于聚合子模型预测的不同策略并创建包含房屋数据特征和聚合策略的模型输入后,只需调用集成模型的 predict 方法即可获得聚合的房屋价格预测。
使用不同策略评估模型性能
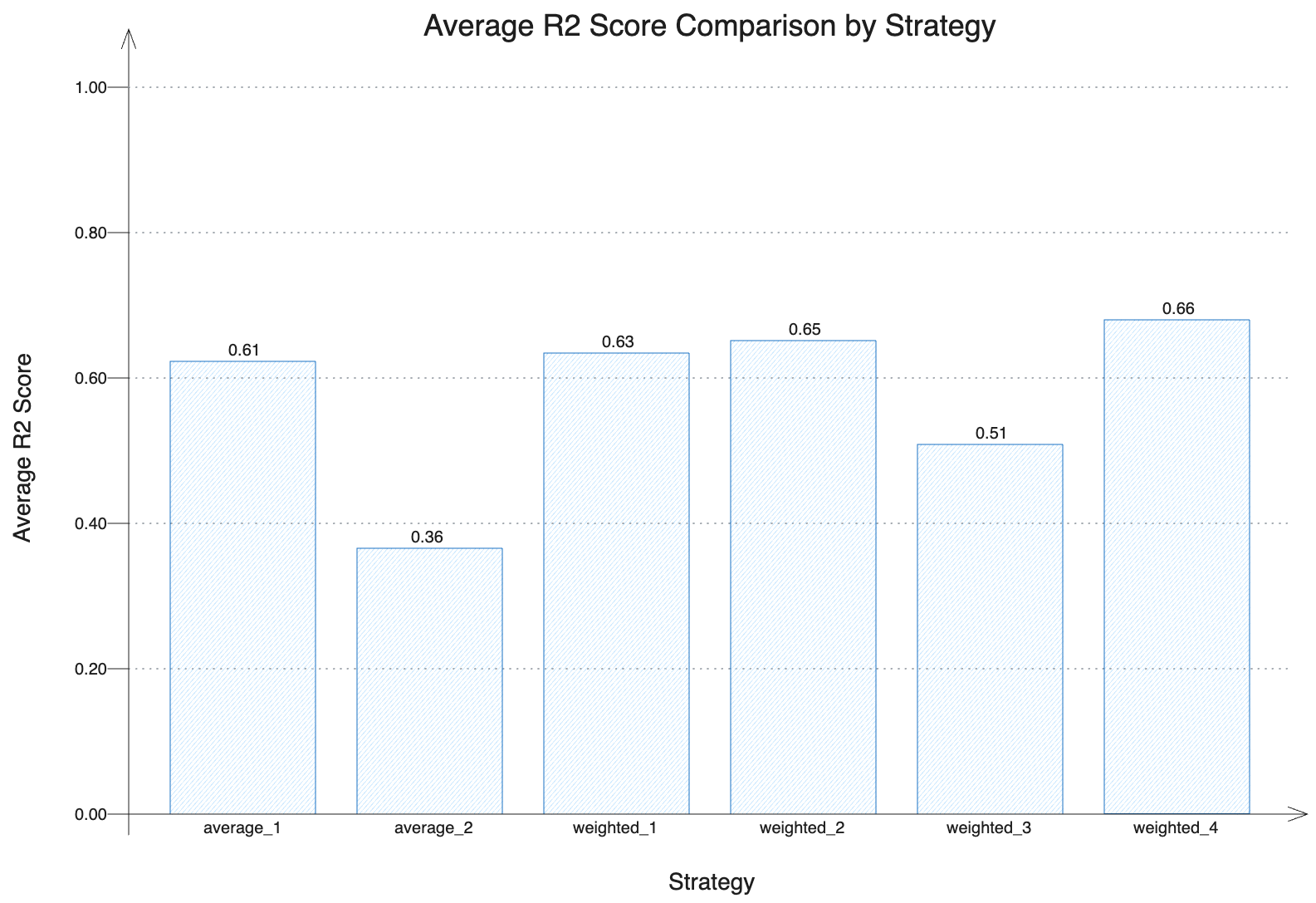
为了评估我们集成模型的性能,我们计算了不同聚合策略的平均 R² 分数。这些策略包括简单的平均以及子模型的加权组合,具有不同的模型配置及其各自的权重。通过比较 R² 分数,我们可以评估哪些策略提供了最准确的预测。
下图以条形图形式展示了每种策略的平均 R² 分数。更高的值表示更好的预测性能。如图所示,集成策略通常优于单个模型(如我们第二个依赖于单个 DecisionTree 的策略 (average_2) 所示),这证明了聚合多个子模型预测的有效性。这种直观的比较突显了使用集成方法的优势,特别是对于优化每个子模型贡献的加权策略。
总结
本博文重点介绍了 mlflow.pyfunc 的功能及其在机器学习项目中的应用。MLflow 的这项强大功能提供了创作自由度和灵活性,使团队能够在 MLflow 中将复杂的系统构建为模型,并遵循与传统模型相同的生命周期。本文展示了集成模型设置的创建、与 DuckDB 的无缝集成以及使用此多功能模块实现自定义方法。
除了提供一种实现预期结果的结构化方法外,本博文还基于实践经验展示了实际可能性,讨论了潜在的挑战及其解决方案。
其他资源
探索以下资源,以更深入地了解 MLflow PyFunc 模型: