MLflow 中的模型代码日志记录 - 是什么、为什么以及如何

我们都(嗯,大部分人)还记得 2022 年 11 月 OpenAI 公开发布 ChatGPT,这标志着人工智能领域的一个重要转折点。尽管生成式人工智能 (GenAI) 已经发展了一段时间,但基于 OpenAI 的 GPT-3.5 架构构建的 ChatGPT 迅速抓住了公众的想象力。这导致了 GenAI 在科技行业和公众中的兴趣爆炸式增长。
在工具方面,MLflow 继续巩固其作为 ML 社区机器学习运维 (MLOps) 首选工具的地位。然而,GenAI 的兴起对我们使用 MLflow 的方式提出了新的需求。这些新挑战之一是如何在 MLflow 中记录模型。如果您之前使用过 MLflow(我敢打赌您用过),您可能熟悉 mlflow.log_model() 函数及其如何高效地 pickle 模型工件。
特别是在 GenAI 方面,有一个新需求:从“代码”记录模型,而不是将其序列化为 pickle 文件!猜猜怎么着?这个需求不限于 GenAI 模型!因此,在这篇文章中,我将探讨这个概念以及 MLflow 如何适应以满足这一新需求。
您会注意到此功能是在一个非常抽象的层面实现的,允许您将任何模型“作为代码”记录,无论是 GenAI 还是其他!我喜欢将其视为一种通用方法,GenAI 模型只是其用例之一。因此,在这篇文章中,我将探讨这个新功能——“代码日志模型”。
阅读完本文,您应该能够回答三个主要问题:“是什么”、“为什么”以及“如何”使用代码日志模型。
什么是代码日志模型?
事实上,当 MLflow 发布此功能时,它让我以更抽象的方式思考“模型”的概念!如果您放大并考虑模型是一个描述输入和输出变量之间关系的数学表示或函数,您可能会觉得这很有趣。
甚至可能有人会意识到,模型作为对象或工件,只是模型可能的一种形式,即使它是 ML 社区中最受欢迎的一种。如果您仔细想想,模型也可以像一个映射函数的代码片段,或者发送 API 请求到 OpenAI API 等外部服务的代码一样简单。
我将在稍后的文章中详细解释如何从代码记录模型的详细工作流程,但现在,让我们先从高层次上考虑它,分两步进行:首先,编写模型代码;其次,从代码记录模型。这将如下所示:
代码日志模型高层工作流程:

🔴 重要的是要注意,当我们提到“模型代码”时,我们指的是可以被视为模型本身的代码。这意味着它**不是**生成已训练模型对象的训练代码,而是作为模型本身执行的步骤式代码。
代码日志模型与基于对象的日志模型有何不同?
在上一节中,我们讨论了代码日志模型的概念。然而,当与它们的替代方案进行对比时,概念通常会变得更清晰;一种称为*对比学习*的技术。在我们的案例中,替代方案是基于对象的日志模型,这是 MLflow 中记录模型的常用方法。
基于对象的日志模型将训练好的模型视为一个可以存储和重用的*对象*。训练完成后,模型将作为对象保存,并可以轻松加载以进行部署。例如,可以通过调用 mlflow.log_model() 来启动此过程,MLflow 将处理序列化,通常使用 Pickle 或类似方法。
基于对象的日志模型可以分为三个高层步骤,如下所示:首先,创建模型对象(无论是通过训练还是获取);其次,对其进行序列化(通常使用 Pickle 或类似工具);第三,将其作为对象进行记录。
基于对象的日志模型高层工作流程:

💡 流行于用的基于对象的日志模型与代码日志模型的主要区别在于,前者记录模型对象本身,无论是您训练的模型还是您获取的预训练模型。然而,后者记录*表示*模型的代码。
何时需要代码日志模型?
到目前为止,我希望您已经清楚地理解了代码日志模型*是什么*!但是,您可能仍在想,这个功能具体有哪些用例。本节将详细介绍——为什么!
虽然我们在介绍中提到了 GenAI 作为一个激励性的用例,但我们也强调了 MLflow 在代码日志模型方面采取了更通用的方法,我们将在下一节中看到这一点。这意味着您可以利用代码日志功能的通用性来应对各种场景。我已确定了三个我认为特别相关的关键使用模式:
1️⃣ 当您的模型依赖于外部服务时:
这是显而易见且常见的用例之一,尤其是在现代 AI 应用兴起之时。我们越来越清楚地看到,我们正从“模型”粒度转向“系统”粒度来构建 AI。
换句话说,AI 不再仅仅是关于单个模型;而是关于这些模型如何在更广泛的生态系统中交互。随着我们越来越依赖外部 AI 服务和 API,对代码日志模型的需求变得更加明显。
例如,像 LangChain 这样的框架允许开发人员构建应用程序,将各种 AI 模型和服务链接在一起以执行复杂任务,例如语言理解和信息检索。在这种情况下,“模型”不仅仅是一组可以*pickle*的训练好的参数,而是一个由相互连接的服务组成的“系统”,通常由调用外部平台 API 的代码进行编排。
在这种情况下,代码日志模型确保了整个工作流程,包括逻辑和依赖关系,都被保留下来。它通过捕获代码来提供相同的模型体验,能够忠实地重现模型的行为,即使实际的计算工作是在您的域之外执行的。
2️⃣ 当您组合多个模型来计算复杂指标时:
除了 GenAI,您仍然可以在各种其他领域受益于代码日志功能。在许多情况下,需要组合多个专用模型来产生全面的输出。请注意,我们不只是指传统的集成建模(预测同一变量);通常,您需要组合多个模型来预测复杂推断任务的不同组成部分。
一个具体的例子可能是客户分析中的客户生命周期价值 (CLV)。在 CLV 的背景下,您可能拥有独立的模型用于:
- 客户留存:预测客户将继续与企业互动多久。
- 购买频率:预测客户的购买频率。
- 平均订单价值:估算每次交易的典型价值。
这些模型中的每一个可能都已经使用 MLflow 进行了适当的记录和跟踪。现在,您需要将这些模型“组合”成一个单一的“系统”来计算 CLV。我们称之为“系统”,因为它包含多个组件。
MLflow 代码日志模型的优点在于,它允许您将此“CLV 系统”视为一个“CLV 模型”。它使您能够利用 MLflow 的功能,保持 MLflow 式的模型结构,并拥有跟踪、版本化和部署 CLV 模型作为统一单元的所有优势,即使它构建在其他模型之上。虽然可以使用自定义 MLflow PythonModel 来构建如此复杂的模型系统,但利用代码日志功能极大地简化了序列化过程,减少了构建解决方案的摩擦。
3️⃣ 当您根本没有序列化时:
尽管深度学习兴起,但行业仍然依赖于不产生序列化模型的基于规则的算法。在这些情况下,代码日志模型有助于将这些流程集成到 MLflow 生态系统中。
一个例子是工业质量控制,其中 Canny 边缘检测算法通常用于识别缺陷。这种基于规则的算法不涉及序列化,而是由特定的步骤定义。
另一个如今日益受到关注的例子是 因果 AI。基于约束的因果发现算法,如 PC (Peter-Clark) 算法,可以在数据中发现因果关系,但它是作为代码而不是模型对象实现的。
在这两种情况下,通过代码日志功能,您可以将整个过程作为“模型”记录在 MLflow 中,保留逻辑和参数,同时受益于 MLflow 的跟踪和版本化功能。
如何实现代码日志模型?
希望到目前为止,您已经清楚地理解了代码日志模型的“是什么”和“为什么”,现在您可能渴望动手实践,并专注于“如何”!
在本节中,我将提供一个实现 MLflow 代码日志模型的通用工作流程,然后是一个基础但广泛适用的示例。我希望该工作流程能提供广泛的理解,让您能够应对各种场景。我还会附上相关资源链接,介绍更具体的用例(例如 AI 模型)。
代码日志模型工作流程:
实现的一个关键“组成部分”是 MLflow 的组件 pyfunc。如果您不熟悉它,可以将 pyfunc 视为 MLflow 中的一个通用接口,通过定义一个*自定义* Python 函数,您可以将任何框架的任何模型转换为 MLflow 模型。如果您想更深入地了解,也可以参考这篇之前的博文。
对于我们的代码日志模型,我们将特别使用 pyfunc 中的 PythonModel 类。MLflow Python 客户端库中的这个类允许我们创建和管理 Python 函数作为 MLflow 模型。它使我们能够定义一个自定义函数来处理输入数据并返回预测或结果。然后,可以使用 MLflow 的功能来部署、跟踪和共享此模型。
这似乎正是我们所需要的——我们有一些代码充当我们的模型,我们想记录它!这就是为什么您很快就会在我们的代码示例中看到 mlflow.pyfunc.PythonModel!
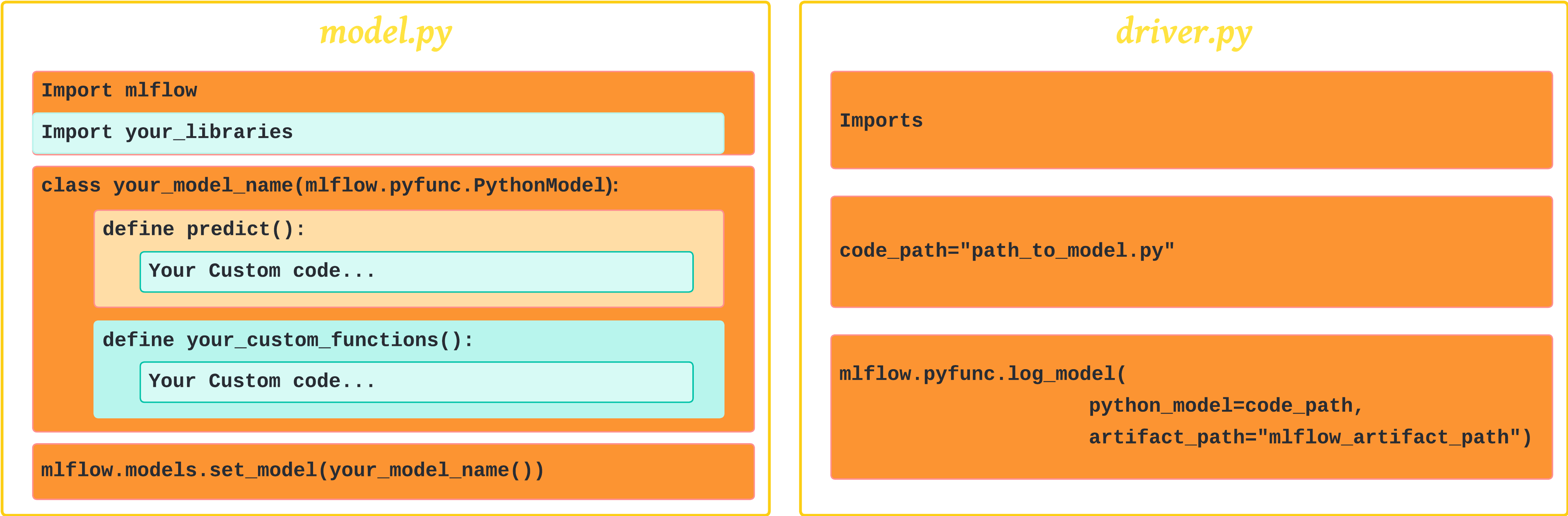
现在,每次我们需要实现代码日志模型时,我们都会创建*两个*独立的 Python 文件:
-
第一个包含我们的模型代码(我们称之为
model_code.py)。此文件包含一个继承自mlflow.pyfunc.PythonModel类的文件。我们定义的类包含我们的模型逻辑。它可以是我们对 OpenAI API 的调用、CLV(客户生命周期价值)模型,或者是我们的因果发现代码。我们很快就会看到一个非常简单的 101 示例。📌 但等等!重要提示
- 我们的
model_code.py脚本需要调用(即包含)mlflow.models.set_model()来设置模型,这对于使用load_model()加载模型以进行推理至关重要。您将在示例中注意到这一点。
- 我们的
-
第二个文件记录我们在
model_code.py中定义的类。将其视为驱动代码;它可以是笔记本电脑或 Python 脚本(我们称之为driver.py)。在此文件中,我们将包含负责记录模型代码的代码(本质上是提供model_code.py的路径)。
然后我们可以部署我们的模型。稍后,当服务环境加载时,model_code.py 将被执行,当收到服务请求时,将调用 PyFuncClass.predict()。
此图提供了这两个文件的通用模板。
代码日志模型的 101 示例:
让我们来看一个简单的例子:一个根据直径计算圆面积的简单函数。通过代码日志模型,我们可以将此计算记录为模型!我喜欢将其视为将计算框架化为预测问题,允许我们用 predict 方法编写模型代码。
1. 我们的 model_code.py 文件:
import mlflow
import math
class CircleAreaModel(mlflow.pyfunc.PythonModel):
def predict(self, context, model_input, params=None):
return [math.pi * (r ** 2) for r in model_input]
# It's important to call set_model() so it can be loaded for inference
# Also, note that it is set to an instance of the class, not the class itself.
mlflow.models.set_model(model=CircleAreaModel())
2. 我们的 driver.py 文件:
这也可以在笔记本电脑中定义。以下是其基本内容:
import mlflow
code_path = "model_code.py" # make sure that you put the correct path
with mlflow.start_run():
logged_model_info = mlflow.pyfunc.log_model(
python_model=code_path,
artifact_path="test_code_logging"
)
#We can proint some info about the logged model
print(f"MLflow Run: {logged_model_info.run_id}")
print(f"Model URI: {logged_model_info.model_uri}")
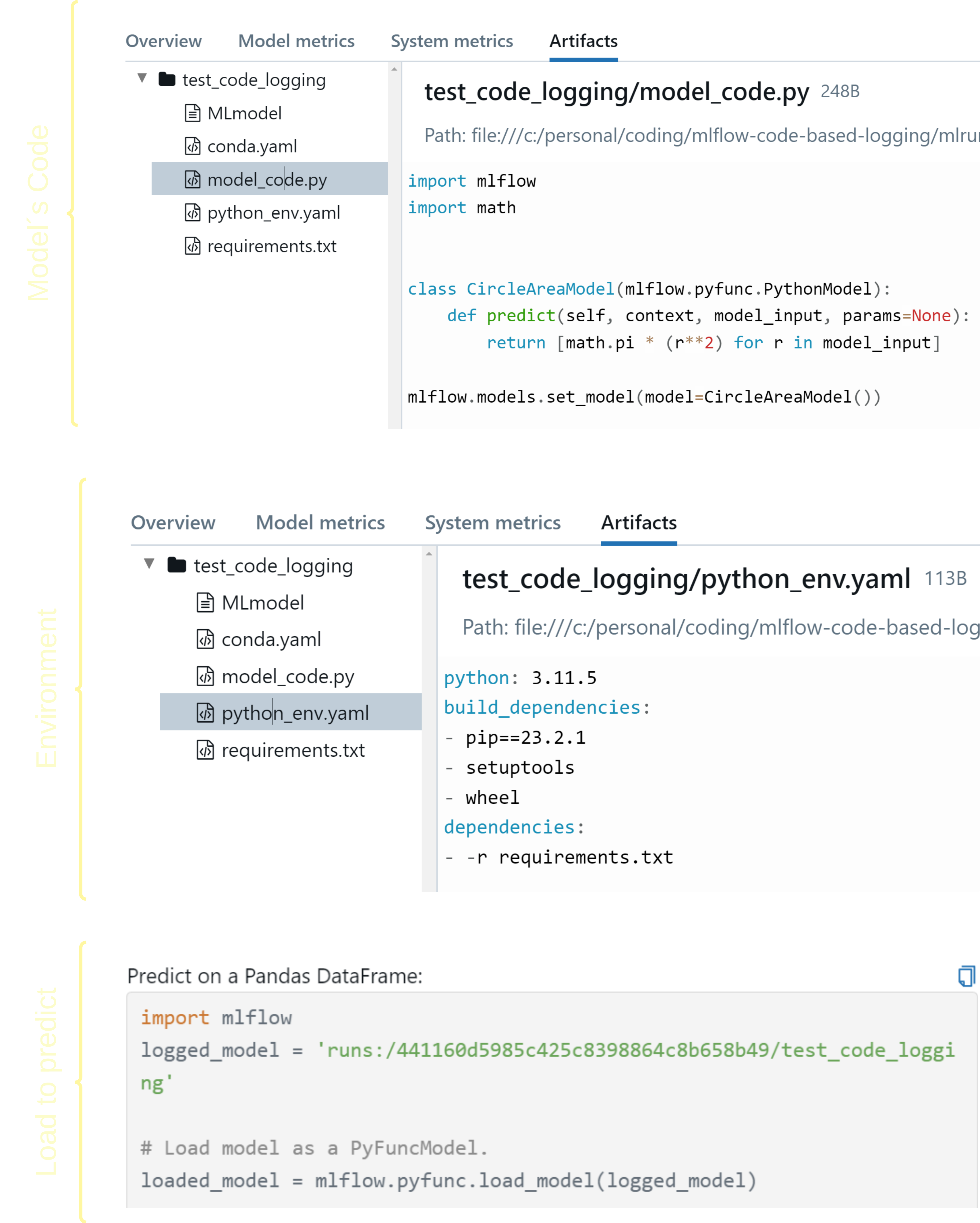
在 MLflow 上看起来是这样的:
执行 driver.py 将启动 MLflow 运行并将我们的模型作为代码记录。文件如图所示:
结论和进一步学习
希望到目前为止,我已经兑现了我的承诺!您现在应该对代码日志模型*是什么*以及它与流行的基于对象的日志模型(将模型记录为序列化对象)有更清晰的理解。您还应该对*为什么*以及何时使用它有一个坚实的基础,并且通过我们的通用示例了解*如何*实现它。
正如我们在介绍和整篇文章中所提到的,代码日志模型在各种用例中都有好处。我们的 101 示例只是一个开始——还有很多东西需要探索。以下是一些代码示例,您可能会觉得有帮助: