使用 mlflow.autolog 进行自动指标、参数和 artifact 日志记录

想了解更多关于 MLflow 中内置的 autologging 功能吗?那么,这份关于使用此强大且节省时间的特性的基础知识入门指南就是您正在寻找的!
强大的日志记录实践是机器学习模型迭代开发和改进的核心。在处理复杂的机器学习库或试验多个具有不同 API 和不同对象/值追踪选择的框架时,仔细追踪指标、参数和构件可能会很具挑战性。
MLflow 的**自动日志记录功能**提供了一个简单的解决方案,兼容许多广泛使用的机器学习库,例如 PyTorch、Scikit-learn 和 XGBoost。使用 `mlflow.autolog()` 可以指示 MLflow 捕获关键数据,而无需用户手动指定要捕获的内容。它是 MLflow 日志记录功能的一个易于访问且强大的入口点。
要启用自动日志记录,只需在您的机器学习脚本/笔记本中,在开始可能包含您想记录的信息或构件的模型训练或评估活动之前,添加以下一行代码:
import mlflow
mlflow.autolog()
Autolog 功能
当数据科学工作流程包含 `mlflow.autolog()` 时,MLflow 将自动记录:
- 指标:标准的训练和评估度量,例如准确率和 F1 分数;
- 参数:超参数,例如学习率和估计器数量;以及
- 构件:重要文件,例如训练好的模型。
MLflow 的自动日志记录会捕获针对正在使用的库的具体活动的定制化细节:不同的库将产生不同的日志对象和数据。此外,MLflow 还记录关键元数据,例如软件版本、git 提交哈希以及运行启动的文件名。通过记录模型训练期间系统的状态,MLflow 旨在促进环境的可复现性并提供审计沿袭,从而最大程度地减少因较新库版本中的包回归或弃用可能引起的推理问题。
自动日志记录捕获内容的具体细节取决于使用的库。此外,MLflow 还捕获上下文元数据,例如软件版本、git 提交哈希以及启动运行的文件名。通过记录尽可能多的关于训练模型的系统状态的详细信息,MLflow 可以提供环境的可复现性和审计沿袭,从而最大程度地减少例如包回归或弃用所导致的推理问题。
mlflow.autolog 的基本用法
您可以通过两种不同的方式访问自动日志记录功能:
- 通过 `mlflow.autolog()` 函数,该函数启用并配置所有支持库的自动日志记录。这在处理多个库时提供了一种广泛的、一刀切的方法,非常适合原型设计和机器学习管道的探索性分析。
- 通过特定于库的 autolog 函数,例如 `mlflow.sklearn.autolog()`,可以为单个库实现更细粒度的日志记录配置。例如,`mlflow.pytorch.autolog()` 包含 `log_every_n_epoch` 和 `log_every_n_step` 参数,用于指定日志记录指标的频率。
无论您使用这两种方法中的哪一种,您都不需要使用 `start_run()` 手动初始化 MLflow 运行,即可创建运行并让您的模型、参数和指标被捕获到 MLflow 中。
示例
import mlflow
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Generate a 3-class classification problem
X, y = datasets.make_classification(
n_samples=1000,
class_sep=0.5,
random_state=42,
n_classes=3,
n_informative=3,
)
# Split the data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Enable autolog
mlflow.autolog() # or mlflow.sklearn.autolog()
# Initialize the classifier with n_estimators=200 and max_depth=10
clf = RandomForestClassifier(n_estimators=200, max_depth=10)
# Fit the classifier to the data.
# The `fit` method is patched to perform autologging. When engaged in training, a
# run is created and the parameters are logged.
# After the fit is complete, the model artifact is logged to the run.
clf.fit(X_train, y_train)
# Score the model on the data
# The current active run is retrieved during calling `score` and the loss metrics are logged
# to the active MLflow run.
clf.score(X_val, y_val)
# Visualize the automatically logged run results to validate what we recorded
mlflow.last_active_run()
上述代码将模型参数、指标和模型记录到 MLflow 运行中。上面示例中最后一个语句(`mlflow.last_active_run()`)的结果,它将返回模型指标、参数和记录的构件(结果已截断)的数据,如下所示:
<Run: data=<RunData:
metrics={'RandomForestClassifier_score_X_val': 0.72,
'training_accuracy_score': 0.99625,
'training_f1_score': 0.9962547564333545,
'training_log_loss': 0.3354604497935824,
'training_precision_score': 0.9962921348314606,
'training_recall_score': 0.99625,
'training_roc_auc': 0.9998943433719795,
'training_score': 0.99625
},
params={'bootstrap': 'True',
'ccp_alpha': '0.0',
'class_weight': 'None',
'criterion': 'gini',
'max_depth': '10',
'max_features': 'sqrt',
'max_leaf_nodes': 'None',
[...],
},
tags={'estimator_class': 'sklearn.ensemble._forest.RandomForestClassifier',
'estimator_name': 'RandomForestClassifier',
'mlflow.autologging': 'sklearn',
[...]
}, [...]>>
您还可以通过在命令行终端执行 `mlflow ui` 来在 MLflow UI 中访问这些内容。

MLflow UI 还允许您在图形界面中比较多个运行(包括通过 `mlflow.autolog` 生成的运行)之间的不同指标和参数。
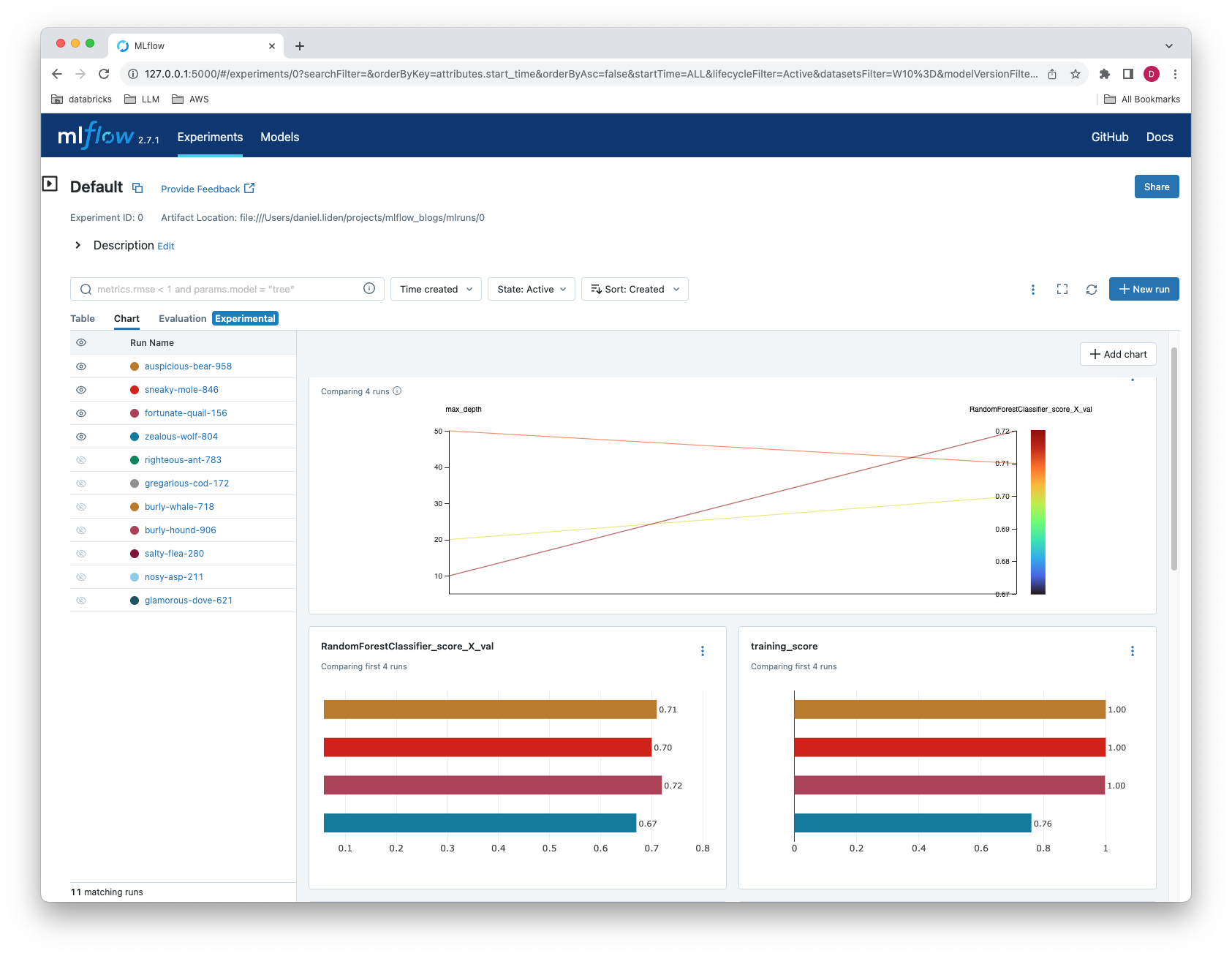
配置和自定义
自动日志记录函数接受许多参数,为用户提供了对日志记录行为的更大控制。例如,`mlflow.autolog()` 包含 `log_models` 和 `log_datasets` 参数(两者默认为 `True`),用于指定是否应将模型和数据集信息保存到 MLflow 运行中,从而允许您指定实际记录的内容。要禁用数据集的自动日志记录,同时继续记录所有常规元素,只需在拟合模型之前将 `log_datasets=False` 设置为 `mlflow.autolog(log_datasets=False)` 来禁用数据集的自动日志记录功能。您还可以调整特定于库的 autolog 函数的行为:例如,`mlflow.sklearn.autolog()` 函数包含一个 `max_tuning_runs` 参数,用于指定在执行超参数搜索时要捕获的嵌套运行数量。
可以结合使用 `mlflow.autolog()` 和特定于库的 autolog 函数来控制特定库的日志记录行为。无论调用顺序如何,特定于库的 autolog 调用始终会覆盖 `mlflow.autolog()`。例如,将 `mlflow.autolog()` 与 `mlflow.sklearn.autolog(disable=True)` 结合使用,将导致除 `scikit-learn` 之外的所有支持库都自动进行日志记录。
查阅您使用的特定框架的文档以了解自动记录的内容以及可用的配置选项非常重要。请参阅下面的进一步阅读部分以获取链接。
结论和后续步骤
MLflow 的 autologging 功能和特定于库的自动日志记录函数提供了一个简单的起点,用于 MLflow 跟踪,几乎不需要或完全不需要配置。它们记录了许多流行的机器学习库中的关键指标、参数和构件,使用户无需编写自定义跟踪代码即可跟踪其机器学习工作流程。
但是,它们并非适用于所有用例。如果您只需要跟踪少量特定指标,启用自动日志记录可能会效率低下,产生比所需更多的生成数据和存储的构件。此外,并非所有可能的框架和用户可能想要跟踪的自定义值都支持自动日志记录。在这些情况下,可能需要手动指定要跟踪的内容。
进一步阅读
- MLflow 关于自动日志记录的文档
- mlflow.autolog 的 Python API 参考
- 特定于库的 autolog 函数的 Python API 参考