使用 MLflow 跟踪图像数据集

数据集跟踪是构建健壮且可复现的机器学习模型的基础。在所有数据类型中,图像由于其高维度、可变性和存储需求,在跟踪方面带来了独特的挑战。在本文中,我们将演示如何使用 MLflow 的实验跟踪功能和 UI 有效地跟踪图像数据集,为您提供实用的技术来增强计算机视觉工作流程中的数据和模型跟踪。
注意:本指南假定您熟悉 MLflow 及其跟踪功能以及 PyTorch。对于初学者,请参考 MLflow 入门教程 和此 PyTorch Vision 教程。
为何跟踪图像数据集?
跟踪图像数据集对于结构化的机器学习项目至关重要。它确保了
- 高质量的训练数据:与结构化数据集不同,图像数据集难以理解和阅读,但它们对模型性能的重要性相同,并且仍然需要标注、整理和特征转换。
- 可复现性:可以通过相同的数据集版本和预处理步骤来重现实验。
- 数据和模型沿袭:跟踪维护数据使用记录,这对于遵守数据治理以及跟踪训练、验证和测试中使用模型的沿袭至关重要。
- 调试:跟踪有助于识别可能影响模型性能的数据质量或预处理问题。
理解图像数据集格式
在全球机器学习社区中存在许多数据集格式。在本博客文章中,我们将使用一种广泛用于计算机视觉模型的格式——COCO,以传统文件格式和同一数据集的 Hugging Face 版本。这两种格式都有优缺点,并且在 MLflow 跟踪方面提供了不同的可能性。
使用原生文件格式的优点
pycocotools/torchvision中可直接使用的数据加载器- 加载速度快
- 文件大小较小
- 简单的目录结构
- 可以跟踪和显示文件,例如作为图像
缺点
- 不可跟踪
- 非结构化数据,搜索和探索可能很混乱
- 不可查询
使用 Hugging Face 数据集 / 表格数据集的优点
- 高度结构化
- 使用
mlflow.data作为训练数据集完全可跟踪(见下文) - 可以为 MLflow 中的数据添加元数据
缺点
- 由于二进制数据以文本形式写入表格条目,文件体积庞大
- 需要自定义数据加载器
COCO:目标在上下文中
COCO 是计算机视觉领域广泛使用的数据集格式,以其丰富的标注而闻名。它支持
- 目标检测、关键点检测、物体分割、图像字幕等。
- 基于 JSON 的标注,用于存储元数据。
我们将在整个博客文章中使用此数据集。
可视化图像数据集中的标注对于执行全面的质量检查很重要。您可以在 COCO 数据集官方网站 上探索数据集,以进一步了解其中包含的数据性质。
图像数据集包含标注,这些标注可以是图片中的物体片段或边界框。这意味着对于每张图像,都会有一个类别和一组每个已识别对象的坐标。请参阅 COCO 数据集的以下示例

Hugging Face 图像数据集
Hugging Face 提供了一个简单的 Image Folder 类型,用于从本地文件创建数据集。它支持
- 元数据集成,用于文本字幕和目标检测。
- 使用目录文件路径快速创建数据集。
这可以与 COCO 等多种格式一起使用,并得到 MLflow 的支持。
使用 MLflow 跟踪数据集
了解数据集的属性对于有效的 ML 模型训练、测试和评估至关重要。这包括分析类别平衡、标注质量和其他关键特征。通过彻底审查源数据的这些方面,您可以确保数据集符合机器学习任务的要求,并识别可能影响模型性能的潜在偏差或差距。因此,数据集需要与模型一起进行跟踪,以在项目的实验和改进过程中。
MLflow 提供强大的工具来确保可复现性和模型沿袭
- 记录数据集元数据,例如格式(例如,COCO、Hugging Face Image Folder)。
- 记录特征转换/数据增强步骤中使用的参数。
- 跟踪数据集版本以实现可复现性。
- 存储和检索与数据集相关的构件,例如数据集描述。
- 将数据集与特定的模型训练运行关联。
支持我们跟踪源数据的一个关键 API 是使用 mlflow.log_artifacts 方法、mlflow.log_input 方法,我们将看到如何结合使用 mlflow.data 模块,在与 Hugging Face 结合使用时,可以为数据集跟踪添加更多结构。我们将使用 mlflow.pytorch 模块文档 来记录一个模型以及我们的数据集跟踪。
使用计算机视觉模型和图像数据集跟踪的示例
有两种方法可以记录图像数据集
- 使用
mlflow.artifacts - 使用
mlflow.data(数据集 API)。
您还可以记录一个 评估数据集,这在本文中不作介绍。
为什么有两种方法?
将 COCO 等基于文件的图像数据集转换为表格格式具有挑战性,因为大多数数据加载器都期望基于文件的 COCO 格式。记录构件提供了一种快速直接的解决方案,无需重新格式化文件。但是,如果您不小心组织目录结构中的文件,这也会变得有点混乱。确保为构件创建有意义的路径。
COCO 数据集的关键构件是 instances.json 文件,它描述了图像数据集的元数据和标注。例如,此文件可用于通过分析 category 字段来检查数据集中的类别平衡。
如果您对此不太关注,Hugging Face 可以帮助以 MLflow 的方式记录数据集。一些 Hugging Face 数据集包含丰富的元数据,可以转移到 MLflow 的跟踪功能中。这就是 mlflow.data 发挥作用的地方。与记录构件相比,这为数据集添加了更丰富的元数据和结构,使其在给定的实验运行中更易于管理和查看。如果您能将数据集纳入 Hugging Face 类型的数据集并在数据加载器或训练脚本中使用它,这就是推荐的方法。
在本文中,我将通过代码介绍这两种方法。
安装 MLflow 和其他依赖项
首先,在您的 python >= 3.10 环境中安装两个代码示例所需的依赖项。如果您只使用第一个示例,则可以省略 opencv;如果您只使用第二个示例,则可以省略 pycocotools。
pip install mlflow datasets torch torchvision pycocotools opencv-python-headless psutil
如果您想跟踪 GPU 指标,也请安装 pynvml。
对于 Hugging Face 数据集下载,请确保也登录。
huggingface-cli login
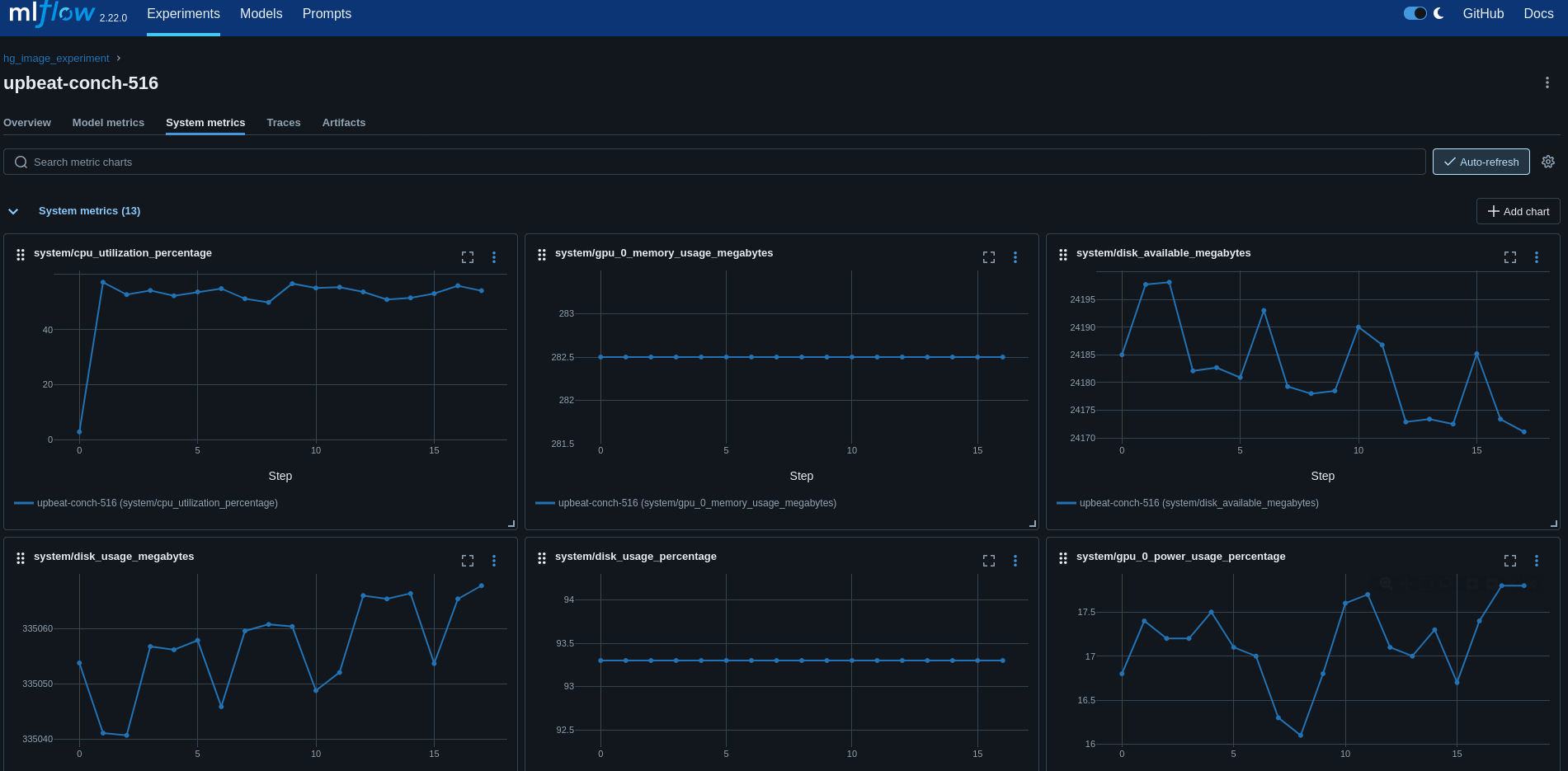
其中一个示例需要计算;因此,请确保启用 MLflow 系统指标 来跟踪训练期间计算上发生的情况。
export MLFLOW_ENABLE_SYSTEM_METRICS_LOGGING=true
注意:使用验证集是为了节省空间,但您也可以使用“训练”集,如果您想在整个数据集上训练/微调模型(需要 +25 GB 存储空间)。训练期间也使用训练轮数和数据集子集。
将数据集作为构件与模型一起记录
由于 COCO 数据集是基于文件的,因此需要先下载文件。我们使用官方作者网站上最新版本数据集中最小的版本。
# download the COCO val 2017 dataset
wget -P datasets http://images.cocodataset.org/zips/val2017.zip
unzip -q datasets/val2017.zip -d datasets
wget -P datasets http://images.cocodataset.org/annotations/annotations_trainval2017.zip
unzip -q datasets/annotations_trainval2017.zip -d datasets
rm datasets/val2017.zip & rm datasets/annotations_trainval2017.zip
现在我们可以训练一个模型,并在同一运行中跟踪训练数据集的构件以及输入。
import json
from torchvision.datasets import CocoDetection
from torchvision import models
import mlflow
# Load a COCO Dataset (val used to limit size)
img_folder = "datasets/val2017"
coco_annotation_file = "datasets/annotations/instances_val2017.json"
# Download dataset
dataset = CocoDetection(img_folder, coco_annotation_file)
# Load a pre-trained model from COCO
model = models.detection.fasterrcnn_resnet50_fpn(weights='COCO_V1')
# Set experiment name
mlflow.set_experiment("coco_experiment")
# Save dataset artifacts and model
with mlflow.start_run():
# log dataset
with open(coco_annotation_file, 'r') as f:
dataset_metadata = json.load(f)
mlflow.log_dict(dataset_metadata, "coco_annotation_file")
# log images
mlflow.log_artifact(img_folder, artifact_path="images")
# log model
mlflow.pytorch.log_model(model, "model")
# register model with a meaningful name
mlflow.register_model(
"runs:/{}/model".format(mlflow.active_run().info.run_id),
"fasterrcnn_resnet50_fpn_coco_2017_model"
)
我们可以在 MLflow UI 中看到数据集已注册到我们模型的实验运行下。
支持图像和文本文件的可视化。
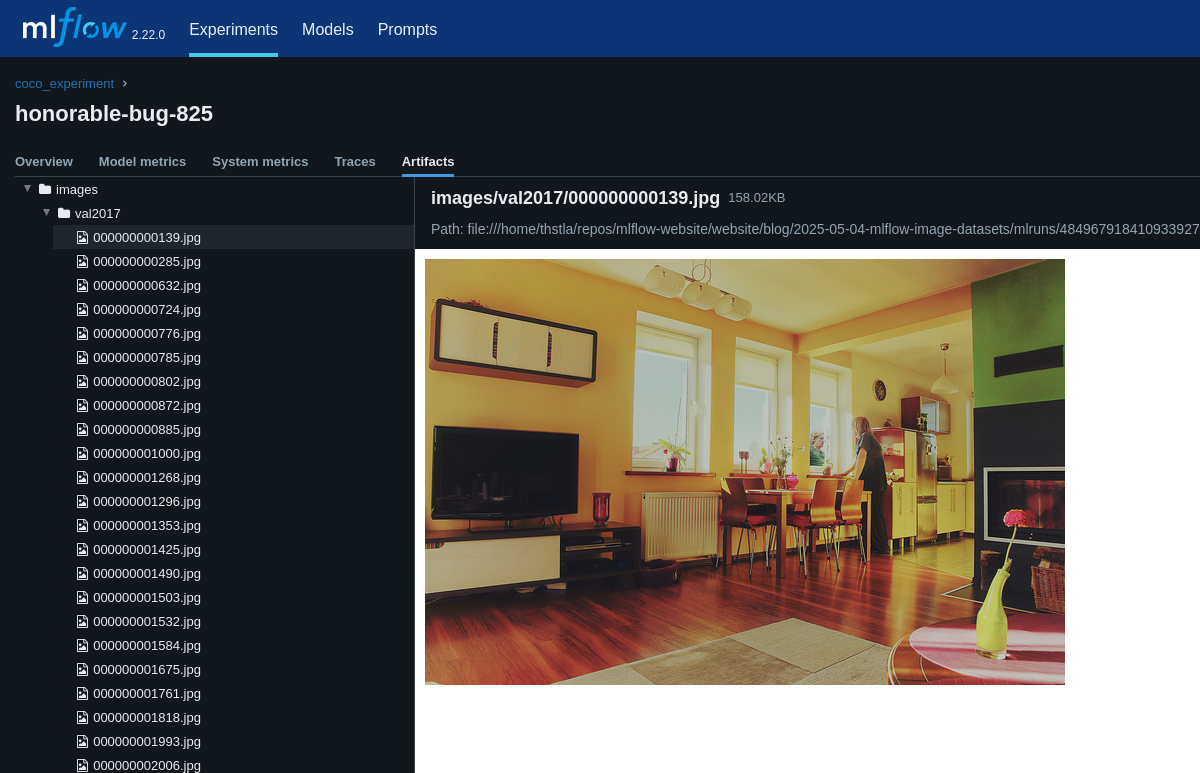
将数据集与模型一起记录
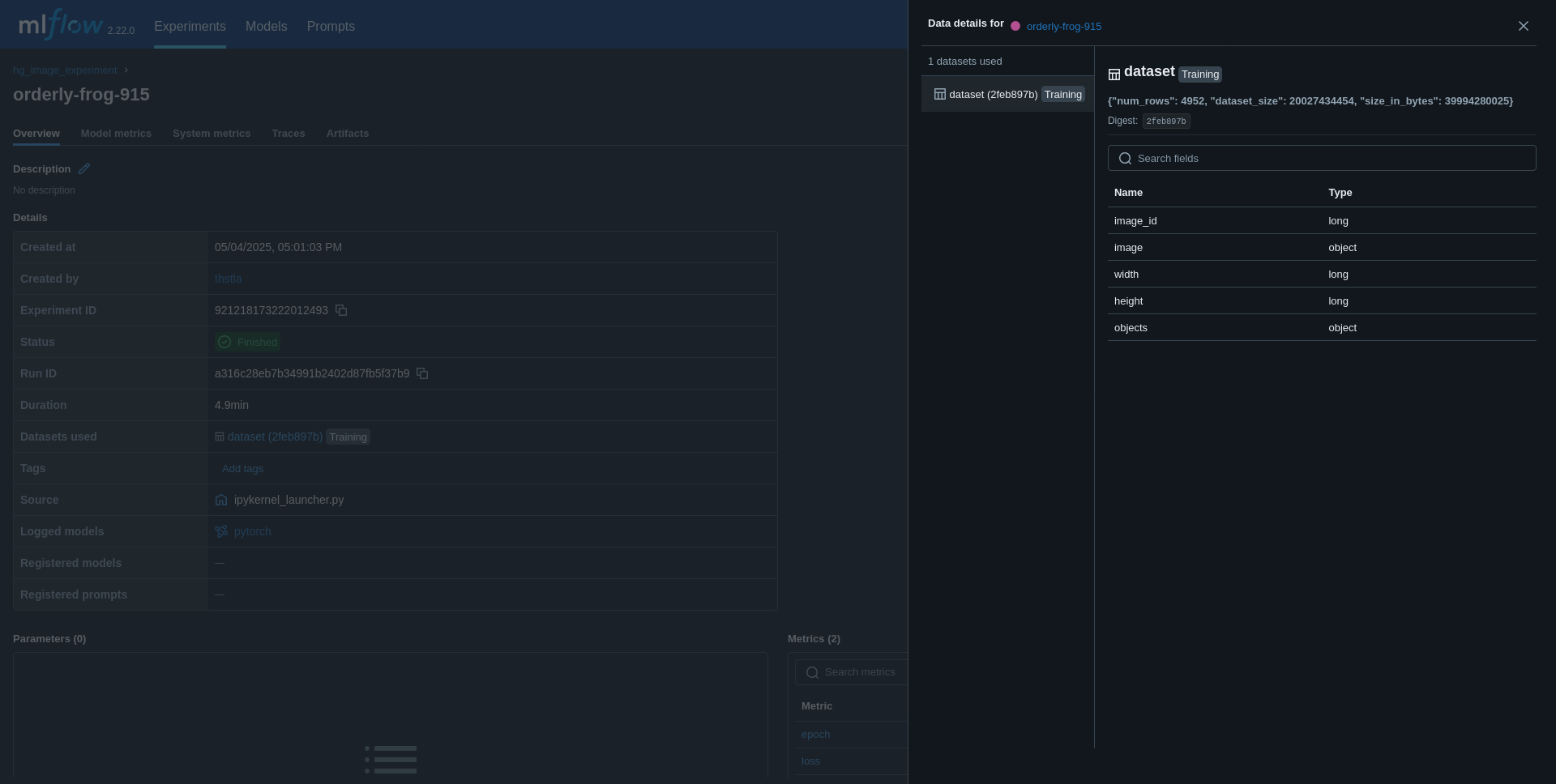
我们可以使用 Hugging Face 数据集以更结构化的方式完成此操作,并利用一种便捷的方式来读取数据。通过这种方式,我们可以在同一个实验运行中拥有 MLflow 跟踪的数据集、训练指标和模型!
import numpy as np
import cv2
import io
import mlflow
from torchvision import models
from torchvision.models.detection import FasterRCNN_ResNet50_FPN_Weights
import os
os.environ["MLFLOW_ENABLE_SYSTEM_METRICS_LOGGING"] = "true"
# Load the COCO dataset from Hugging Face
dataset = load_dataset("detection-datasets/coco", split="val")
# Transform to MLFlow Dataset
mlflow_dataset = mlflow.data.huggingface_dataset.from_huggingface(dataset)
# For this example we create a subset of the dataset with the first 100 rows
subset_dataset = dataset.select(range(100))
# Load a pre-trained object detection / segmentation model
model = models.detection.fasterrcnn_resnet50_fpn(weights=FasterRCNN_ResNet50_FPN_Weights.DEFAULT)
# Let’s fine-tune it, log dataset, metrics, and model in an MLflow Experiment run
mlflow.set_experiment("hg_image_experiment")
with mlflow.start_run():
# log training dataset in model training run
mlflow.log_input(mlflow_dataset, context="training")
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)
for epoch in range(1): # We train for 1 epoch in this example
print(f"Training object detection model, epoch {epoch+1}...")
for row in subset_dataset: # We run a subset of the dataset to save time
# In this example we are not using a dataloader but just converting image bytes to ndarray
image_bytes = io.BytesIO()
row["image"].save(image_bytes, format="JPEG")
image_bytes = image_bytes.getvalue()
if isinstance(image_bytes, bytes):
image_array = np.frombuffer(image_bytes, np.uint8)
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
else:
raise TypeError("Expected bytes object for 'image', got {}".format(type(image_bytes)))
image = np.array(image)
# Prepare annotations as target
annotations = row["objects"]
target = []
for i in range(len(annotations['category'])):
d = {}
d['boxes'] = torch.tensor(annotations['bbox'][i], dtype=torch.float32).reshape(-1, 4) # Ensure shape [N, 4]
d['labels'] = torch.tensor([annotations['category'][i]], dtype=torch.int64) # Wrap in a list for correct shape
target.append(d)
# Convert the image to a PyTorch tensor and normalize it
image_tensor = torch.tensor(image, dtype=torch.float32).permute(2, 0, 1) / 255.0
# Perform forward pass in batches of one
input_batch = [image_tensor]
output = model(input_batch, target)
# Compute loss
loss_dict = output[0] if isinstance(output, list) else output
loss = sum(loss for loss in loss_dict.values())
# Backpropagation and optimization step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Pretty print the loss
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
mlflow.log_metrics({"epoch": epoch+1})
mlflow.log_metrics({"loss": loss.item()})
# finally log model
mlflow.pytorch.log_model(
model,
"model",
input_example=input_batch
)
我们已经展示了如何以表格格式处理图像,以简化 Hugging Face 数据集在训练运行中的使用。
在第二个实验下,您现在将有一个记录的数据集。
局限性
虽然 MLflow 本身功能强大,但它需要支持。请考虑以下局限性
- 存储开销:记录大型数据集可能需要大量的存储空间。
- 标注复杂性:管理复杂的标注可能需要自定义脚本,例如
pycocotools,或像 CVAT 这样的开源工具,后者还提供了图像数据集管理的广泛 UI 功能。 - 可视化:MLflow 的 UI 和 Databricks 尚未针对可视化图像数据集标注进行优化,需要
CVAT或自定义脚本等工具。 - 中央数据集管理:
CVAT还可以帮助管理和版本化将在 MLflow 实验运行中使用的ⱼ数据集。
其他资源
我们希望本指南能帮助您简化使用 MLflow 进行图像数据集跟踪,并为您提供一些关于图像数据集的新想法。祝您 ML 模型训练愉快!
切勿让 GPU/CPU 过热。 在 MLflow UI 中跟踪模型训练期间的系统指标。