使用 MLflow 构建和管理基于 LLM 的 OCR 系统




构建 GenAI 工具会带来一系列独特的挑战。在评估准确性、迭代提示以及实现协作时,我们经常会遇到瓶颈,从而减缓我们迈向生产的进程。
在本博客中,我们将探讨 MLflow 的 GenAI 功能如何帮助我们简化开发,并为技术和非技术贡献者在构建基于 LLM 的光学字符识别 (OCR) 工具时释放价值。
什么是 OCR?
光学字符识别 (OCR) 是从扫描文档和图像中提取文本的过程。生成的文本是机器编码的、可编辑的和可搜索的,从而解锁了广泛的下游用例。
在这里,我们利用多模态 LLM 从扫描文档中提取格式化文本。与 PyTesseract 等传统 OCR 工具不同,基于 LLM 的方法为复杂的布局、手写内容和上下文感知提取提供了更大的灵活性。虽然这些方法可能需要更多的计算资源和仔细的提示工程,但它们为高级用例提供了显著的优势。
有趣的事实:最早的 OCR 形式 Optophone 于 1914 年推出,旨在帮助盲人阅读印刷文本而无需盲文。
挑战
在构建基于 LLM 的 OCR 应用程序时,我们会遇到几个反复出现的挑战。
提示迭代和版本控制:需要更新和调整提示以提高提取质量。新提示可能会导致性能回退,但我们没有保存旧版本。如果没有严格的版本控制,很难回滚或进行比较。
调试意外结果:在我们的 OCR 尝试中可能会定期出现意外结果。我们需要一种方法来理解原因。如果没有详细的可追溯性,就很难诊断问题出在提示、模型还是数据(例如,新的文档结构)。
评估和比较模型:OCR 的准确性可以意味着很多事情。我们可能希望衡量正确的字段提取、格式设置,甚至业务逻辑合规性。为了比较不同的模型或提示策略,我们需要一种方法来定义和跟踪重要内容。
MLflow 在我们的工作流程中直接解决了这些问题。
OCR 用例:
我们的任务是使用 LLM 创建一个用于文本提取 (OCR) 的文档解析工具,并利用 MLflow 功能来解决我们的挑战。数据包括扫描文档及其提取的 JSON 格式的相应文本。
我们使用 FUNSD 数据集,该数据集包含大约 200 个完全注释的表单,结构化为语义实体标签和单词分组。
示例

{
"form": [
{
"id": 0,
"text": "Registration No.",
"box": [94,169,191,186],
"linking": [
[0,1]
],
"label": "question",
"words": [
{
"text": "Registration",
"box": [94,169,168,186]
},
{
"text": "No.",
"box": [170,169,191,183]
}
]
},
{
"id": 1,
"text": "533",
"box": [209,169,236,182],
"label": "answer",
"words": [
{
"box": [209,169,236,182
],
"text": "533"
}
],
"linking": [
[0,1]
]
}
]
}
有关每个条目的详细描述,请参阅 原始论文。
1. 设置
安装所需软件包
pip install openai mlflow tiktoken aiohttp -qU
openai:用于与 OpenAI 模型和 API 交互
mlflow:用于实验跟踪、模型管理和 GenAI 工作流程工具
tiktoken:用于高效的 tokenization,尤其适用于 OpenAI 模型
aiohttp:用于异步 HTTP 请求,可实现高效的 API 调用
在本教程中,我们使用 OpenAI,但该方法适用于其他 LLM 提供商。我们可以提示用户输入 OpenAI API 密钥而不显示回显,使用 getpass()。
import os
from getpass import getpass
os.environ["OPENAI_API_KEY"] = getpass("Your OpenAI API Key: ")
2. 查看数据
让我们读取一个随机选择的图像及其对应的注释 JSON 文件。以下 utils 函数有助于完成此任务。
from __future__ import annotations
from dataclasses import dataclass
from io import BytesIO
from pathlib import Path
from typing import Any, Mapping, Sequence, TypedDict, Literal
import pandas as pd
import base64
import json
import random
import re
from PIL import Image as PILImage
DATA_DIRECTORY = Path("./data")
ANNOTATIONS_DIRECTORY = DATA_DIRECTORY / "annotations"
IMAGES_DIRECTORY = DATA_DIRECTORY / "images"
class Word(TypedDict):
text: str
class Item(TypedDict, total=False):
id: str | int
label: Literal["question", "answer", "other"]
words: list[Word]
linking: list[tuple[str | int, str | int]]
@dataclass(frozen=True)
class QAPair:
question: str
answer: str
def _flatten_form(form: Any) -> list[Item]:
"""
Flattens the 'form' section into a simple list of items.
Accepts list[Item], list[list[Item]], or a single list-like page.
"""
if isinstance(form, list):
if form and all(isinstance(page, list) for page in form):
return [item for page in form for item in page] # 2D -> 1D
return form
raise TypeError("Expected 'form' to be a list or list of lists.")
def extract_qa_pairs(items: Sequence[Mapping[str, Any]]) -> list[QAPair]:
"""
Robustly extract Q&A pairs. Supports multiple answers per question.
Does not assume unique question text; uses ids to match.
"""
by_id: dict[Any, Mapping[str, Any]] = {}
for it in items:
if "id" in it:
by_id[it["id"]] = it
pairs: list[QAPair] = []
for it in items:
if it.get("label") != "question":
continue
links = it.get("linking") or []
q_words = it.get("words") or []
q_text = " ".join(w.get("text", "") for w in q_words).strip()
for link in links:
if not isinstance(link, (list, tuple)) or len(link) != 2:
continue
q_id, a_id = link
if q_id != it.get("id"):
# Skip foreign link edges
continue
ans = by_id.get(a_id)
if not ans or ans.get("label") != "answer":
continue
a_words = ans.get("words") or []
a_text = " ".join(w.get("text", "") for w in a_words).strip()
if q_text and a_text:
pairs.append(
QAPair(
question=q_text,
answer=a_text,
)
)
return pairs
def load_annotation_file(file_name: str | Path, directory: Path = ANNOTATIONS_DIRECTORY) -> list[QAPair]:
"""
Load one annotation JSON and return extracted Q&A pairs.
Always returns a list; empty if none found.
"""
file_path = (directory / file_name) if isinstance(file_name, str) else file_name
if file_path.suffix.lower() != ".json":
file_path = file_path.with_suffix(".json")
with file_path.open("r", encoding="utf-8") as f:
data = json.load(f)
form = data.get("form")
items = _flatten_form(form)
return extract_qa_pairs(items)
def choose_random_annotation_names(
directory: Path = ANNOTATIONS_DIRECTORY,
n: int = 1,
suffix: str = ".json",
seed: int | None = None,
) -> list[str]:
"""
Returns a list of basenames (without extension). Raises if directory missing or empty.
Deterministic when seed is provided.
"""
if not directory.exists():
raise FileNotFoundError(f"Directory {directory} does not exist.")
files = sorted(p for p in directory.iterdir() if p.is_file() and p.suffix.lower() == suffix)
if not files:
raise FileNotFoundError(f"No {suffix} files found in {directory}.")
if seed is not None:
rnd = random.Random(seed)
selected = rnd.sample(files, k=min(n, len(files)))
else:
selected = random.sample(files, k=min(n, len(files)))
return [p.stem for p in selected]
def compress_image(
file_path: str | Path,
*,
quality: int = 40,
max_size: tuple[int, int] = (1000, 1000),
) -> bytes:
"""
Resize and convert to JPEG with the given quality. Returns JPEG bytes.
"""
file_path = Path(file_path)
with PILImage.open(file_path) as img:
img = img.convert("RGB")
img.thumbnail(max_size)
buf = BytesIO()
img.save(buf, format="JPEG", quality=quality, optimize=True)
return buf.getvalue()
def get_image_bytes_or_b64(
file_name: str | Path,
*,
directory: Path = IMAGES_DIRECTORY,
as_base64: bool = False,
quality: int = 40,
max_size: tuple[int, int] = (1000, 1000),
) -> bytes | str:
"""
Returns compressed JPEG bytes or a base64 string. File extension is coerced to .png on input,
but compression always outputs JPEG bytes/base64.
"""
path = (directory / file_name) if isinstance(file_name, str) else file_name
if path.suffix.lower() != ".png":
path = path.with_suffix(".png")
jpeg_bytes = compress_image(path, quality=quality, max_size=max_size)
if as_base64:
return base64.b64encode(jpeg_bytes).decode("utf-8")
return jpeg_bytes
_key_chars_re = re.compile(r"[^\w\s\-_]") # keep word chars, space, dash, underscore
_ws_re = re.compile(r"\s+")
def clean_key(key: str) -> str:
"""Remove unwanted characters, collapse whitespace, trim, and convert to UPPER_SNAKE-ish."""
key = _key_chars_re.sub("", key)
key = _ws_re.sub(" ", key).strip()
# If you prefer underscores: key = key.replace(" ", "_")
return key.upper()
def normalize_dict_keys(obj: Any) -> Any:
"""
Recursively normalize mapping keys; preserves lists/tuples;
"""
from collections.abc import Mapping as ABMapping, Sequence as ABSequence
if isinstance(obj, ABMapping):
return {clean_key(str(k)): normalize_dict_keys(v) for k, v in obj.items()}
if isinstance(obj, (list, tuple)):
return obj.__class__(normalize_dict_keys(v) for v in obj)
return obj
让我们花点时间分解一下 _extract_qa_pairs 函数。
- 我们创建一个 ID 查找字典,以通过 ID 查找项目。
- 我们识别“问题”项,这些项在表单中具有链接的答案对,形式为 (q_id, a_id)。
- 我们通过从问题和答案单词中提取文本来构建结构化的 QAPair 对象。
然后,我们可以调用 load_annotation_file 来加载注释 JSON 文件并返回问题-答案对(结构化的 QAPair 对象)。
对于 LLM 输入,我们倾向于使用小型、可预测的负载,而不是无损保真度。我们使用 get_image_bytes_or_b64 从目录中读取 PNG 图像,并根据 as_base64 的布尔值将其转换为压缩的 JPEG 字节(使用 _compress_image)或 base64。
带宽和成本:PNG 表单扫描通常比相同分辨率的 JPEG 大 5-10 倍。由于我们将图像作为 base64 发送(带有约 33% 的开销),因此缩小字节直接减小了请求大小、延迟和 API 成本——尤其是在批量评估许多页面时。
标准化:转换为 8 位 RGB 并展平透明度消除了 PNG 的怪异之处(alpha、索引调色板、16 位深度等),因此每个图像都能以一致的形式到达模型。这消除了跨提供商的“在我的机器上可用”的摄取问题。
吞吐量优先于完美:我们的页面是高对比度的表单,因此适度的 JPEG 压缩可以保持文本清晰,同时显着缩小文件。在本教程中,我们还将分辨率降低到最大边长为 1000 像素,这对于字段标签通常足够了,同时加快了端到端运行和评估的速度。
权衡与不转换:对于微小的字体、低对比度扫描或使用经典 OCR(例如 Tesseract)时,我们更倾向于使用无损格式(PNG/TIFF)或使用更高的 JPEG 质量。压缩伪影会模糊细小的笔画并影响准确性。
random_files = choose_random_annotation_names(n=1, seed=42)
image_bytes = get_image_bytes_or_b64(random_files[0], as_base64=True)
load_annotation_file(random_files[0])
3. MLflow 跟踪、自动日志记录和追踪
在调用 OpenAI 之前,我们需要设置 MLflow Tracking,以确保每个实验、提示和结果都被记录和可追溯。
我们还将启用 MLflow Autolog,通过减少手动日志记录语句的需求来简化跟踪过程。下面,我们将 MLflow 指向本地 SQLite 数据库作为后端存储,其中会自动记录指标、参数、构件和其他有用信息。
import mlflow
mlflow.set_tracking_uri("sqlite:///mlflow_runs.db")
mlflow.set_experiment("ocr-initial-experiment")
mlflow.openai.autolog()
MLflow Tracing 为我们提供了端到端的可见性。我们可以全面了解从提示构建和模型推理到工具调用和最终输出的每个步骤。如果我们注意到 OCR 工具中存在各种失败尝试,我们可以使用 MLflow UI 来检查追踪、比较输入和输出,并确定问题是出在提示、模型还是数据结构上。
要访问 MLflow UI,我们需要运行以下命令。UI 将默认在 https://:5000 上启动。
mlflow ui --backend-store-uri sqlite:///mlflow_runs.db
4. 加载输入和提示
我们首先定义一个系统提示,用于使用 LLM 将图像内容提取到“问题”和“答案”列表中。我们将使用一个“第一遍”提示,该提示故意做得简短且描述性最低,以便以后可以进行改进。当为每个图像文件调用 LLM 完成调用时,这些都会在 MLflow 实验运行中进行跟踪。我们将 QAPair 对象转换为字典,以便在评估期间更容易与 LLM 响应进行比较。
from collections import defaultdict
_files = choose_random_annotation_names(n=5, seed=42)
#Store multiple answers per question as list
annotation_items = []
for file_name in _files:
file_dict = defaultdict(list)
for pair in load_annotation_file(file_name):
file_dict[pair.question].append(pair.answer)
annotation_items.append(dict(file_dict))
annotation_normalized = normalize_dict_keys(annotation_items)
images = [get_image_bytes_or_b64(file, as_base64=True) for file in _files]
system_prompt = """You are an expert at Optical Character Recognition (OCR). Extract the questions and answers from the image."""
5. 设置 LLM
在 OpenAI 端,我们初始化客户端并向 LLM 发送一个提示,指示它充当 OCR 专家。预期输出是包含键值对列表的结构化输出。为了强制执行此结构,我们可以定义 Pydantic 模型来验证响应格式。让我们尝试调用 LLM 并记录执行情况,看看响应是什么样的。
from pydantic import BaseModel
from openai import OpenAI
# Define Pydantic models for structured output in the form of key-value pair accounting for duplicate questions
class KeyValueModel(BaseModel):
key: str
value: list[str]
class KeyValueList(BaseModel):
pairs: list[KeyValueModel]
client = OpenAI()
def get_completion(inputs: str) -> str:
completion = client.chat.completions.parse(
model="gpt-4o-mini",
response_format=KeyValueList,
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": [
{ "type": "text", "text": "what's in this image?" },
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{inputs}",
},
},
],
}
],
)
generated_response = {pair.key: pair.value for pair in completion.choices[0].message.parsed.pairs}
return normalize_dict_keys(generated_response)
with mlflow.start_run() as run:
predicted = get_completion(images[0])
print(predicted)
以下屏幕截图代表了此特定图像提取的问题和答案。

提示注册表
提示工程是基于 LLM 的 OCR 的核心,但创建初始提示通常是不够的。为了跟踪在迭代过程中哪个提示版本产生了哪些结果,我们将使用 MLflow Prompt Registry。这使我们能够注册、版本化和添加标签到提示。
这是一个提示模板示例,它专门指示 LLM 以我们期望的格式生成结果。
new_template = """You are an expert at Optical Character Recognition (OCR). Extract the questions and answers from the image as a JSON object, where the keys are questions and the values are answers. If there are no questions or answers, return an empty JSON object {}.
"""
这个初始提示可以与提示名称、提交消息和相关标签一起注册。注册后,以后可以使用 mlflow.genai.load_prompt() 检索它以供重用或进一步改进。
# Register a new prompt for OCR question-answer extraction
new_prompt = mlflow.genai.register_prompt(
name="ocr-question-answer",
template=new_template,
commit_message="Initial commit",
tags={
"author": "author@example.com",
"task": "ocr",
"language": "en",
},
)
prompt = mlflow.genai.load_prompt(name_or_uri="ocr-question-answer", version=new_prompt.version)
system_prompt = prompt.template
6. 定义和评估性能
作为 ML 工程师,我们确保使用 LLM 的 OCR 应用程序能够根据地面真相进行稳健评估。评估 OCR 系统时,我们关注的不仅仅是准确性。我们可能会查看格式合规性、业务逻辑或字段提取结果。 MLflow Evaluate 允许我们定义与我们的用例相符的 内置和自定义指标。
虽然 MLflow 支持 LLM 作为评判者指标,但对于此 OCR 示例,使用确定性指标更好且成本更低。例如,我们可以定义一个自定义指标 key_value_accuracy 来检查生成输出的键值对是否与地面真相正确匹配。
from mlflow.metrics.base import MetricValue
from mlflow.models import make_metric
def batch_completion(df: pd.DataFrame) -> pd.Series:
result = [get_completion(image) for image in df["inputs"]]
return pd.Series(result)
def key_value_accuracy(predictions: pd.Series, truth: pd.Series) -> MetricValue:
"""
Calculate accuracy scores by comparing predicted dictionaries with ground truth dictionaries.
Both predictions and truth are expected to be dict[str, list[str]] format.
"""
scores = []
for pred_dict, truth_dict in zip(predictions, truth):
if not isinstance(pred_dict, dict) or not isinstance(truth_dict, dict):
scores.append(0.0)
continue
correct = 0
total_answers = 0
for question, truth_answers in truth_dict.items():
total_answers += len(truth_answers)
if question in pred_dict:
pred_answers = pred_dict[question]
# Count how many truth answers are correctly predicted
for truth_ans in truth_answers:
if truth_ans in pred_answers:
correct += 1
scores.append(correct / total_answers if total_answers > 0 else 0.0)
return MetricValue(
scores=scores,
aggregate_results={
"mean": sum(scores) / len(scores) if scores else 0.0,
"p90": sorted(scores)[int(len(scores) * 0.9)] if scores else 0.0
}
)
custom_key_value_accuracy = make_metric(
eval_fn=key_value_accuracy,
greater_is_better=True,
name="key_value_accuracy",
)
定义此自定义指标后,我们可以在包含 base64 编码图像子集及其对应地面真相字典的数据框上对其进行评估。使用 batch_completion 函数,我们在该子集上运行批量完成请求,并以预定义的结构化输出格式检索输出。
results = mlflow.models.evaluate(
model=batch_completion,
data=pd.DataFrame({"inputs": images, "truth": annotation_normalized}),
targets="truth",
model_type="text",
predictions="predictions",
extra_metrics=[custom_key_value_accuracy]
)
print("Custom metric results:", results.metrics)
eval_table = results.tables["eval_results_table"]
print("\n Per-row scores:")
print(eval_table[['key_value_accuracy/score']])
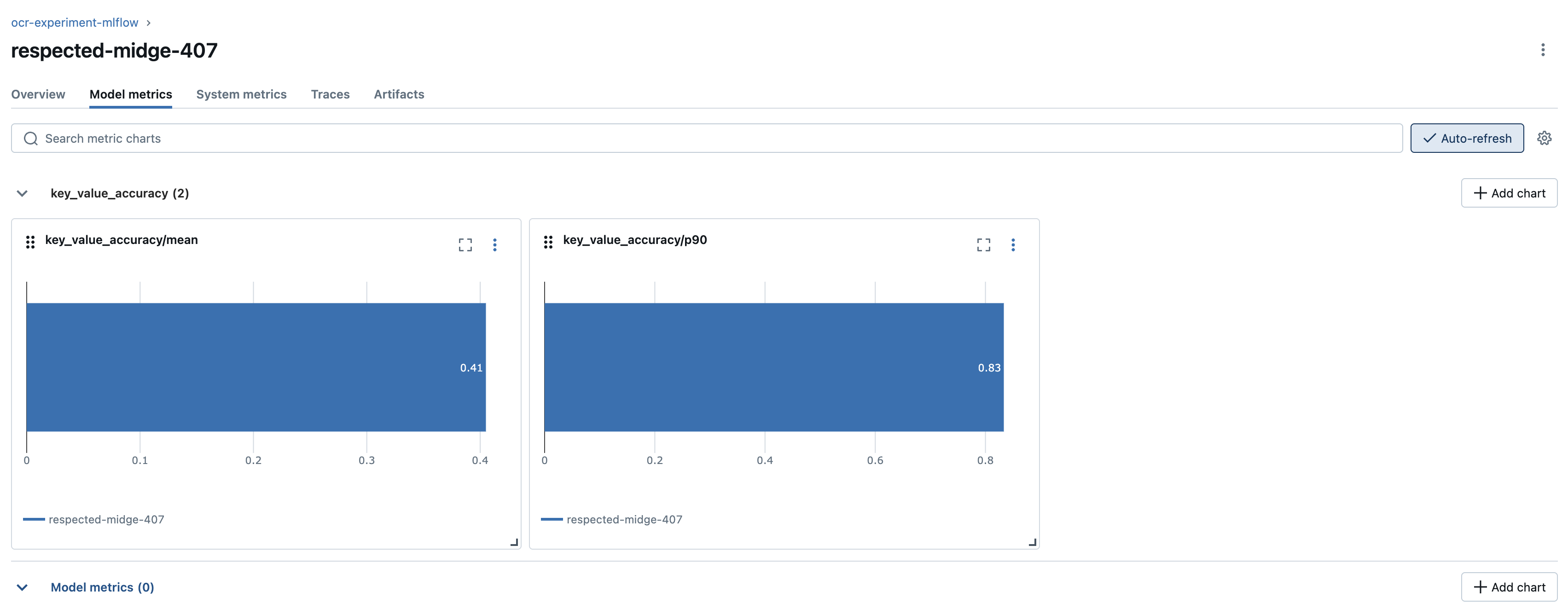
此指标要求地面真相中的键值对与 LLM 生成的输出之间精确匹配。在查看每张图像的单个分数后,我们观察到模型在最后一张图像上的表现最差。具体来说,其中一个键被错误地生成为 CHAINS - ACCEPTANCEMERCHANDISING 而不是 CHAINS ACCEPTANCE/ MERCHANDISING。在其他键中也可以观察到类似的模式,其中不同的主题被不当分隔或不必要地改写。
为解决此问题,我们可以通过明确指示模型使用 / 分隔符分隔不同的主题来优化提示模板。此外,我们可以指示 LLM 避免改写主题中的内容,而是侧重于保持与图像文本的精确匹配。
updated_template = """\
You are an expert at key information extraction and OCR. Extract the questions and answers from the image, where the keys are questions and the values are answers.
Question refers to a field in the form that takes in information. Answer refers to the information
that is filled in the field.
Follow these rules:
- Only use the information present in the text and do not paraphrase.
- If the keys have multiple topics, separate them with a slash (/)
{{ additional_rules }}
"""
下一步是注册更新的提示模板,稍后将其加载回来,并在重新运行评估之前对其进行任何其他规则的格式化。
updated_prompt = mlflow.genai.register_prompt(
name="ocr-question-answer",
template=updated_template,
commit_message="Update commit",
tags={
"author": "author@example.com",
"task": "ocr",
"language": "en",
},
)
# Load the updated prompt and format it with additional rules
prompt = mlflow.genai.load_prompt(name_or_uri="ocr-question-answer", version=updated_prompt.version)
system_prompt = prompt.format(additional_rules="Use exact formatting you see in the form.")
results_updated = mlflow.models.evaluate(
model=batch_completion,
data=pd.DataFrame({"inputs": images, "truth": annotation_normalized}),
targets="truth",
model_type="text",
predictions="predictions",
extra_metrics=[custom_key_value_accuracy]
)
print("Custom metric results:", results_updated.metrics)
eval_table_updated = results_updated.tables["eval_results_table"]
print("\n Per-row scores:")
print(eval_table_updated[['key_value_accuracy/score']])
这个更新的提示可能会为每张图像的指标带来边际改进。但是,地面真相和 LLM 响应之间仍然存在值不匹配的情况。如上所示,使用 Prompt Registry,通过迭代优化提示可以解决这些问题,从而更好地与预期输出保持一致。
结论和后续步骤
通过利用 MLflow GenAI 功能,我们可以高效地管理 OCR 工具的提示并评估模型。随着所有运行、提示和指标的记录,我们可以在 MLflow UI 中并排比较不同的模型或提示策略。这使得能够做出数据驱动的决策,证明模型选择的合理性,并使技术和非技术贡献者能够自信地协作、迭代和部署 AI 解决方案。
我们可以从几个方向着手,进一步增强我们的工作流程和成果。
扩展自定义指标:扩展我们的自定义评估指标,以更准确地捕获特定 OCR 问题的要求。这使我们能够衡量对用例真正重要的内容,例如特定领域的准确性、格式合规性或业务逻辑符合性。
试验多个 LLM:利用 MLflow 的跟踪和比较实验的能力,通过与不同的 LLM 进行迭代。我们可以在 MLflow UI 中并排查看和分析结果,从而更容易确定哪个模型最适合我们的需求,并通过清晰、数据驱动的证据来证明模型选择的合理性。
利用追踪和模型日志记录:利用 MLflow 的追踪和模型日志记录功能,获得对我们 GenAI 工作流的端到端可见性。通过捕获详细的追踪和日志,我们可以在自定义指标的背景下迭代优化我们的模型和提示,诊断问题,并确保可重用性。
扩展治理和访问控制:实施稳健的治理实践,以确保安全、合规且可审计地管理我们的 GenAI 资产和工作流。这对于在企业或受监管的环境中进行扩展尤其重要。
这些只是我们可以构建此解决方案的众多方法中的几种。无论我们的目标是提高模型性能、简化协作还是将解决方案扩展到新领域,这些 MLflow 功能都支持我们的 GenAI 开发。
进一步阅读
实用的 AI 可观测性:MLflow 追踪入门
超越 Autolog:为新 LLM 提供商添加 MLflow 追踪
LLM 作为评判者